MySQLの一般的な分割ライブラリおよび分割テーブルスキームの概要
I. データベースのボトルネック
IOボトルネックであれCPUボトルネックであれ、最終的にはデータベースへのアクティブな接続数が増加し、データベースが担えるアクティブな接続数の閾値に近づくか、あるいは到達することになります。サービスから見ると、これはデータベースへの接続がほとんどない、あるいは全くないことを意味します。次に何が起こるか想像してみてください(同時実行性、スループット、クラッシュ)。
1. IOボトルネック
最初の:ディスクの読み取りIOボトルネック、あまりにも多くのホットデータは、データベースキャッシュが収まらない、各クエリは、クエリの速度を低減し、IOの多くを生成します->サブベースと垂直分割テーブル。
タイプ2:ネットワークIOボトルネック、要求されるデータが多すぎて、ネットワーク帯域が足りない -> サブバンク。
2: CPUボトルネック
1つ目:SQLの問題、例えばSQLを含む結合、group by、order by、非インデックスフィールド条件クエリなど、CPUオペレーションを増加させる -> SQL最適化、正しいインデックスの構築、ビジネスサービス層でのビジネス計算などです。
2つ目:1つのテーブルのデータ量が多すぎる、クエリ時にスキャンする行数が多すぎる、SQLの効率が悪い、CPUが最初のボトルネックになる -> 水平テーブル分割。
第2回:ライブラリとテーブルの分割
1. 水平方向の分岐
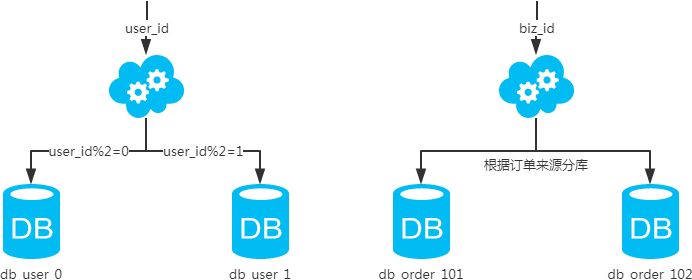
コンセプト フィールドに基づき、ある戦略(ハッシュ、レンジなど)に従って、1つのライブラリから複数のライブラリにデータを分割する。
結果
- 各ライブラリで同じ構成です。
- 各ライブラリごとに異なるデータで、交差がない。
- 全ライブラリを連結したものが全データ量となる。
シナリオ システムの絶対的な並行性が出てきて、テーブルを分割しても根本的な解決にはならないし、リポジトリを縦に分割する明白なビジネス上の帰結もまだない。
分析する。 ライブラリが増えれば、当然ioやCPUの圧迫は指数関数的に緩和されます。
2. テーブルの水平分割
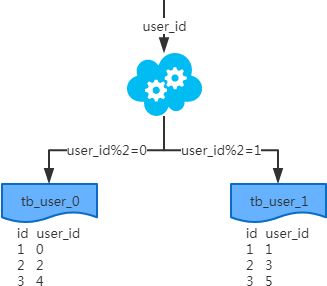
コンセプト
フィールドに基づき、ある戦略(ハッシュ、レンジなど)に従って、1つのテーブルから複数のテーブルにデータを分割する。
結果
- 各テーブルとも同じ構造です。
- 各テーブルは異なるデータを持ち、交差しない。
- すべてのテーブルをデータ量いっぱいに連結したもの。
シナリオ システムの絶対的な並行性は出てこないが、1つのテーブルのデータ量だけが多すぎて、SQLの効率に影響し、CPUに負担がかかり、ボトルネックになっている。おすすめです。SQLクエリの最適化原理を一挙に分析
分析する。 テーブルのデータ量が少なくなり、1回のSQL実行が効率的になり、当然CPUの負荷も軽減されます。
3. 垂直方向への分岐
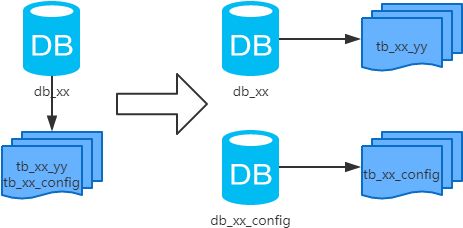
コンセプト テーブルをベースに、ビジネスアトリビュートに応じて異なるリポジトリに分割する。
結果
- ライブラリごとに異なる構造。
- 各ライブラリも異なるデータを持ち、交わることはない。
- 全ライブラリを連結したものが全データ量になります。
シナリオ システムの絶対的な並行性が出てきて、別のビジネスモジュールに抽象化することができる。
分析する。 この時点では、基本的に提供可能な状態になっています。
例えば、ビジネスが成長するにつれて、共通の設定テーブルや辞書テーブルなどが増えてきますが、それらを別のライブラリに分割し、サービス化することも可能です。そして、ビジネスが成長し、一連のビジネスパターンがインキュベートされると、関連するテーブルを別のライブラリに分割したり、サービス化したりすることができます。
4. 縦型テーブル分割
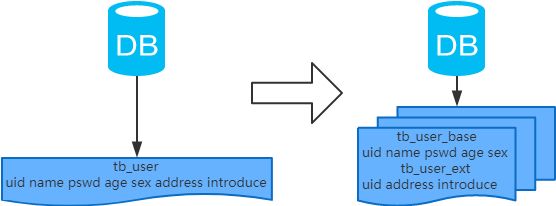
コンセプト
テーブルのフィールドを、フィールドの活動に応じて異なるテーブル(主テーブルと拡張テーブル)に分割すること。
結果
- 各テーブルの構成は異なります。
- もそれぞれ異なり、一般に各テーブルには少なくとも1つの交差するフィールドの列があり、通常は主キーとしてデータの関連付けに使用されます。
- すべてのテーブルを連結したものが、全データ量となる。
シナリオ システムの絶対的な並行性は出てこない、テーブルのレコード数は多くないが、フィールド数が多く、ホットデータと非ホットデータを合わせると、1行のデータに必要な記憶容量が大きくなってしまう。そのため、データベースキャッシュのデータ行数が少なくなり、クエリがディスクデータに行くため、ランダムリードIOが多く発生し、IOボトルネックとなる。
分析する。 一覧ページと詳細ページで理解することができます。縦割りテーブルを分割する原理は、ホットデータ(冗長でよくクエリされる可能性のあるデータ)をメインテーブルとしてまとめ、ホットでないデータを拡張テーブルとしてまとめることである。こうすることで、より多くのホットデータをキャッシュすることができ、ランダムリードIOを減らすことができます。分割後、すべてのデータを取得するには、データを取得するために2つのテーブルを関連付ける必要があります。
なぜなら、CPU負荷が増加するだけでなく、2つのテーブルを結合してしまうからです(これらはデータベースインスタンス上になければなりません)。データを関連付けるには、ビジネスサービスレベルで行い、メインテーブルと拡張テーブルのデータを別々に取得し、関連フィールドを使用してそれらすべてを関連付ける必要があります。
III. データベースの分割とテーブルの分割ツール
- sharding-sphere:jar、以前はsharding-jdbc。
- TDDL: jar、Taobao Distribute Data Layer。
- Mycat:ミドルウェア。
注:ツールの長所・短所については、公式サイトやコミュニティを優先して、ご自身でお調べください。
IV. ライブラリとテーブルを分割するための手順
容量(現在の容量と成長率)からサブバンクやサブテーブルの数を評価する -> キーの選択(偶数) -> テーブルの分割ルール(ハッシュや範囲など) -> 実行(一般的にダブルライト) -> スケーリングの問題(データの移動を最小限に抑える)。
V. 分割ライブラリとテーブルの問題
1、非パーティション・キー・クエリーの問題
水平分割ライブラリとテーブルをベースに、分割戦略は一般的なハッシュ方式を採用。
パーティションキーに加え、最後に条件クエリとして非パーティションキーが1つだけ存在します。
マッピング方法
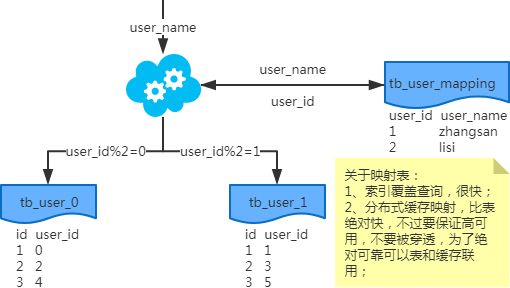
遺伝的手法
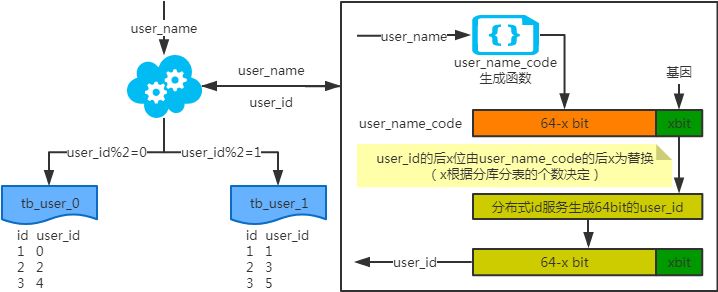
注)書き込みの際、geneメソッドでは図のようにuser_idが生成されます。xbit遺伝子については、例えば8つのテーブルに分割する場合、23=8なのでxは3、すなわち3bit遺伝子をとります。user_idを元にクエリする場合、対応するサブベースやサブテーブルへ直接モーダルルートを取ることができる。
user_nameに基づいて問い合わせる場合、user_name_code関数がuser_name_codeを生成し、対応するブランチやテーブルにルーティングします。id生成はsnowflakeアルゴリズムでよく使用されます。
パーティションキーに加え、非パーティションキーを条件付きクエリとして使用する場合の例を以下に示します。
マッピング方法
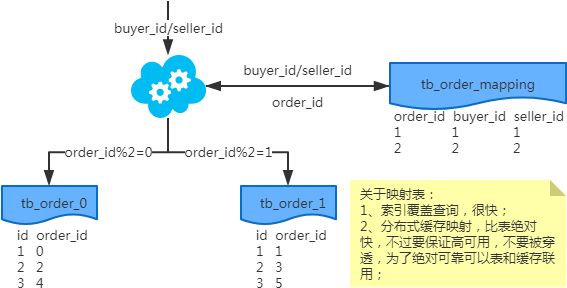
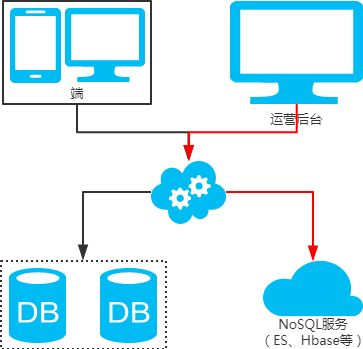
冗長化方式
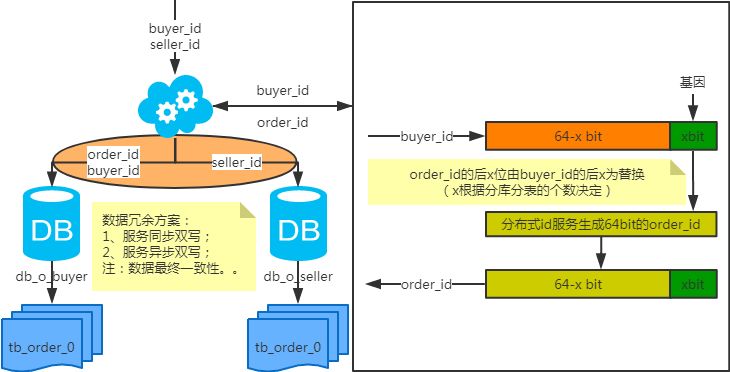
注:order_id や buyer_id でクエリを実行すると db_o_buyer ライブラリにルーティングされ、 seller_id でクエリを実行すると db_o_seller ライブラリにルーティングされます。馬より先にカートを置くような感じです。他に良い方法はないでしょうか?技術スタックを変えてみてはどうでしょうか?
パーティションキーに加え、バックエンドにはパーティションキー以外の様々な組み合わせの条件クエリが存在します。
NoSQL方式
冗長化方式
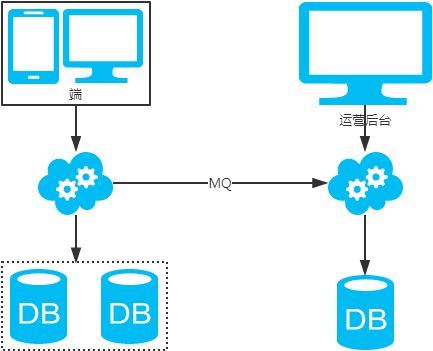
2. 非パーティションキー・クロスライブラリ・クロステーブル・ペイジングクエリ問題
水平分割されたライブラリとテーブルに基づいて、分割戦略は一般的なハッシュ法である。
注)NoSQL方式(ES等)で解決。
3. スケーリングの問題
水平分岐とテーブル分割に基づき、分割戦略は一般的なハッシュ方式です。
リポジトリの水平展開(リポジトリ方式からのアップグレード)
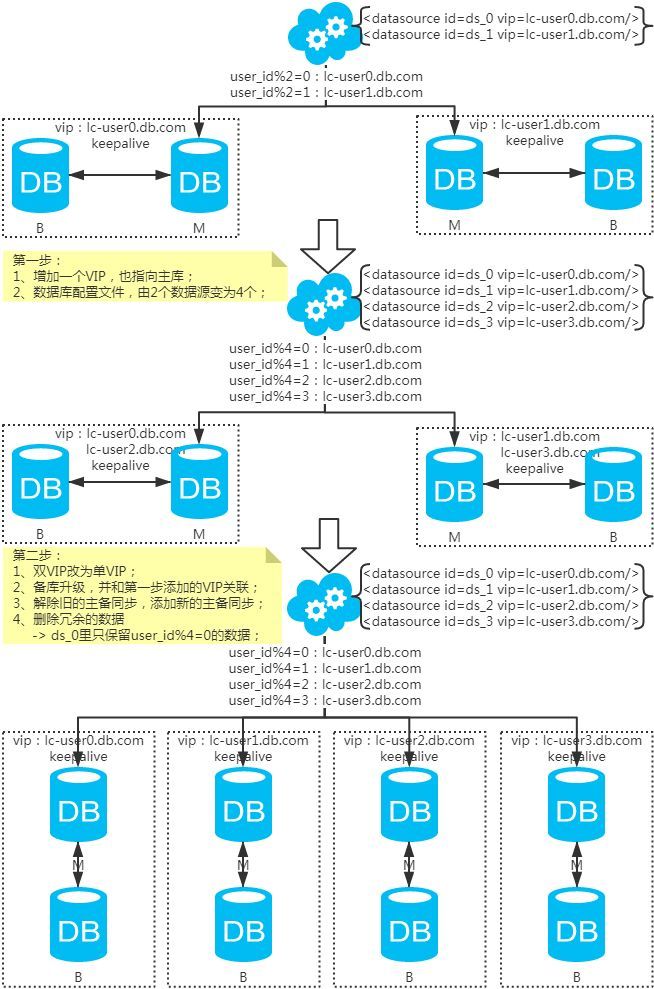
注:拡張は指数関数的に行われます。
水平展開表(ダブルライティング移行方式)
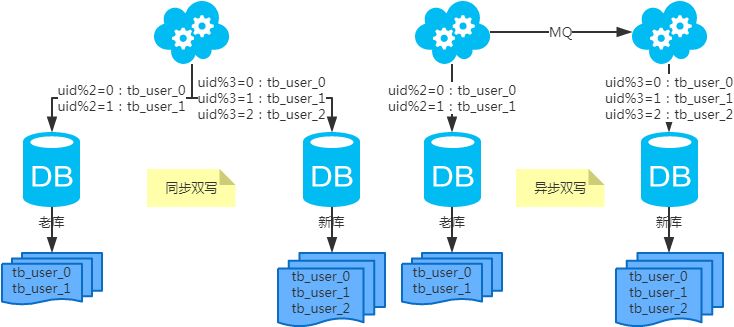
Step 1: (二重書きの同期) アプリケーションの設定とコードを変更し、二重書きを追加してデプロイします。
ステップ2:(ダブルライティングの同期)古いデータを古いリポジトリから新しいリポジトリにコピーします。
ステップ3:(Synchronize double writes)新しいライブラリの古いデータを古いライブラリと照らし合わせて校正する。
ステップ 4: (二重書き込みの同期) アプリケーションの設定とコードを修正し、二重書き込みを削除してデプロイします。
<ブロッククオート注:ダブルライティングは一般的な解決策です。
VI. 分割ライブラリ・分割テーブルの概要
ライブラリとテーブルを分割するには、まずボトルネックがどこにあるのかを知り、合理的に分割する(ライブラリかテーブルか)。水平か垂直か?何本?).そして、分割のための分割はしないことです。
キー選択は、均等に分割する場合にも、分割しないキークエリの場合にも重要です。
分割ルールは、要件を満たしていればシンプルなほどよい。
MySQLよく使われる分割ライブラリと分割テーブルの解決策まとめ」の記事は以上です。もっと関連するMySQL分割ライブラリと分割テーブルの内容は、スクリプトハウスの過去の記事を検索するか、次の関連記事を引き続き閲覧してください。
関連
-
MySQL Innodb インデックスメカニズム詳細解説
-
MySQLデータベース・インデックスの左端一致の原則
-
MySQLで正規表現を使う 詳細
-
mysqlインデックスが長すぎる特殊なキーが長すぎる解決策
-
Mysqlのソート機能の詳細
-
[解決済み】MySQLで「すべての派生テーブルは独自のエイリアスを持つ必要があります」というエラーは何ですか?
-
[解決済み】ValueError: 値の長さがインデックスの長さと一致しない|Pandas DataFrame.unique()
-
mysql5.7のインストールと、無料・長期利用を目的としたNavicateの導入プロセスについて
-
SQLException。オペランドは1列でなければなりません。
-
msql クエリでのエラー 'where 節' の不明な列 'yellow fruit'
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
MySQLのデータバックアップにmysqldumpを使用する方法
-
mysqlでインデックスに障害が発生する原因は何ですか?
-
MySQLにおけるorder byの使用方法の詳細
-
mysqlにおけるvarcharの日付比較とソートの実装
-
MySQLデータベースでvarchar型の数値の大きさを比較する方法
-
MySQLはこのようなUpdateステートメントを書くべきではありません
-
[解決済み] SQLエラー。ORA-01861:リテラルは、フォーマット文字列01861に一致しません。
-
Mysql がエラーを報告 オペランドには 1 つのカラムが含まれている必要があります。
-
Mysql がエラーを報告 オペランドには 1 つのカラムが含まれている必要があります。
-
SQL Server のトランザクションは、try キャッチに記述しなければ、中間ステートメントがエラーを報告してもコミットされます。