Python百行で韓服サークルの画像クロールを実現する
旅行をしていると、観光地でいろいろな衣装を着て写真を撮っている観光客をよく見かけますが、あまり意図的に気にすることはないですよね。2日前、ウェブを見ていて、あるサイトを見たとき、中国の衣装を着た女の子たちが実に格好いいことに気がついた。仕事でも、コピーでも、こういうきれいな写真を素材にするのは、ニーズがあるから、登る、登る、登る!(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)」と、言っていました。
さっそくですが、以下、画像クローリングについて詳しく説明します。
ウェブサイトを分析する
URLは以下の通りです。
https://www.aihanfu.com/zixun/tushang-1/
これは、上記のウェブサイトの通し番号1である2ページ目のURLが2となり、全ページにアクセスできるようになるという観測から、1ページ目のURLとしたものです。
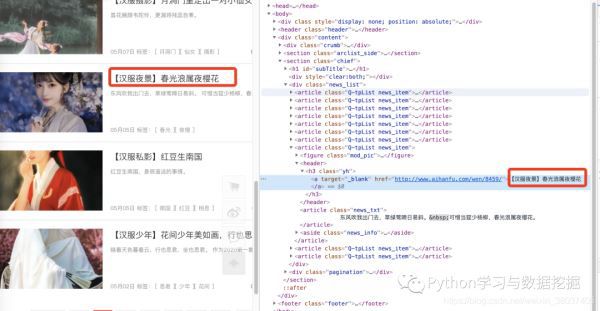
図によると、各サブサイトのリンク、つまりhrefのURLを取得して、各URLにアクセスして、画像のURLを探して、ダウンロードすればいいんですね。
サブリンクの取得
上の図のデータを取得するためには、soupやreなどのメソッドを使うか、xpathを使うことができる。この記事では、エディタはxpathを使ってlocateを行い、locate関数を書き、各サブサイトのリンクを取得し、main関数に戻るというものですが、ここではfor loopで、ある仕掛けが使われています、チェックしてみてください。
public String toString() {
// The schemaMappings are initialized in getSchemaMappings()
return "EntityResolver using mappings " + getSchemaMappings();
}
タイトルと画像アドレスの取得
できるだけ多くのデータを収集するために、我々は、タグと画像のアドレスを取る、もちろん、他のプロジェクトは、出版社と時間を収集する必要がある場合、それはまた、より多くを行うことが可能ですが、この記事は拡大されません。
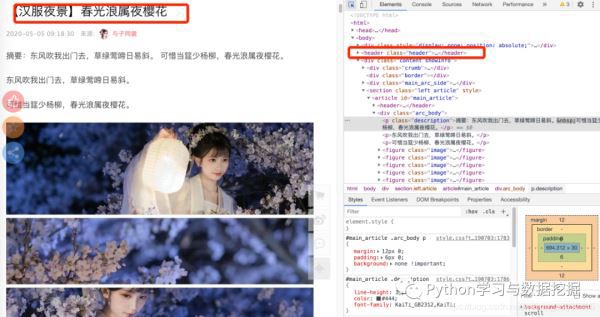
上記のようにURLリンクをクリックすると、headノード内にタイトルがあり、タイトルの取得はフォルダー作成時に使用するためであることがわかります。
コードは以下の通りです。
def get_page(url, headers):
"""
Get the image address based on the subpage link, then package it for download
params: url subURL
"""
r = requests.get(url, headers=headers)
if r.status_code == 200:
r.encoding = r.apparent_encoding
html = etree.HTML(r.text)
html = etree.tostring(html)
html = etree.fromstring(html)
# Get the title
title = html.xpath(r'//*[@id="main_article"]/header/h1/text()')
# Get the image address
img = html.xpath(r'//div[@class="arc_body"]//figure/img/@src')
# title preprocessing
title = ''.join(title)
title = re.sub(r'[|]', '', title)
print(title)
save_img(title, img, headers)
画像の保存
各ページをめくりながら、サブリンクに対応する画像を保存する必要がありますが、ここではリクエストの状態とパスに注意する必要があります。
def save_img(title, img, headers):
"""
Create subfolders based on titles
Download all img links and choose to change the quality size
params: title : title
params: img : image address
"""
if not os.path.exists(title):
os.mkdir(title)
# Download
for i, j in enumerate(img): # iterate through the list of URLs
r = requests.get(j, headers=headers)
if r.status_code == 200:
with open(title + '//' + str(i) + '.png', 'wb') as fw:
fw.write(r.content)
print(title, 'The first of ', str(i), 'The download is complete!')
主な機能
if __name__ == '__main__':
"""
Find one page at a time
params : None
"""
path = '/Users/********/Hanbok/'
if not os.path.exists(path):
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
# url = 'http://www.aihanfu.com/zixun/tushang-1/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/81.0.4044.129 Safari/537.36'}
for _ in range(1, 50):
url = 'http://www.aihanfu.com/zixun/tushang-{}/'.format(_)
for _ in get_menu(url, headers):
get_page(_, headers) # Get a page
これまで我々はすべてのリンクを完了し、クローラの記事は、私は一度以上の紹介、一方では、私はあなたがクローラのスキルをより身近にすることができます願って、他方では、私はクローラがデータ分析、データマイニングの基礎であると思います。データを取得するためのクローラーがない、どのようにデータ分析する。
上記は、韓服サークル画像クロールを達成するためのコードのpython百行の詳細であり、韓服サークル画像をクロールpythonの詳細については、スクリプトハウスの他の関連記事に注意を払うしてください!.
関連
-
[解決済み】Imageという名前のモジュールがない
-
Pythonで数行のコードでdablを使ったデータ処理解析とML自動化
-
[解決済み] ImportError: request という名前のモジュールがない
-
[解決済み] Django - ''の逆が見つかりません。'' は有効なビュー関数またはパターン名ではありません。
-
[解決済み] Python3 Tkinterのフォントが動作しない
-
[解決済み] pandasデータフレームの行をその合計で正規化する [重複] 。
-
[解決済み] pygame.key.get_pressed() が動作しない。
-
AttributeError: 'dict' object has no attribute 'has_key' in Python3 の解決策を紹介します。
-
ソリューションエラーです。PEP 517 を使用する暗号用ホイールがビルドできず、直接インストールすることができない
-
python 3.x エラー 'generator' オブジェクトに 'next' 属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonコードの可読性を向上させるツール「pycodestyle」の使い方を詳しく解説します
-
[解決済み】PythonのTypeErrorはintではなくstrでなければならない【重複あり
-
[解決済み】AttributeError: .dt アクセサは、datetimelike 値でしか使用できません。
-
[解決済み】エラー「ERROR: pipを使用してdjango-herokuをインストールしようとすると、「Command errored out with exit status 1: python.
-
画像に自動的に虹の効果を加えるOpenCVの例
-
クリックのシミュレーションのためのPythonによるゲームランタイムスクリプト
-
[解決済み] 公式略称: import scipy as sp/sc
-
[解決済み] Python のための同等な matlab damp 関数
-
[解決済み] 2文字列間の削除距離
-
[解決済み] NameError: 名前 'request' が定義されていません。