RedisClusterが16,384個のスロットを持つ設計になっている理由
学生の皆さん、Redisクラスタを使ったことがありますか?そして、Redisクラスタの原理は何ですか?次の2つの文章を覚えてください。
- Redis Sentinalは高可用性を重視しており、マスターがダウンしても自動的にスレーブをマスターに昇格させ、サービスを提供し続けることができます。
- Redis Clusterはスケーラビリティを重視しており、単一のRedisがメモリ不足になった場合、Clusterを使用してストレージをシャーディングします。
I. データシャード戦略
分散データストレージソリューションの最も重要な側面は,シャーディングとも呼ばれるデータシャーディングです.クラスタを水平方向に拡張できるようにするためには,データセット全体を特定のルールに従って複数のノードに分散させる方法が主な問題となります.データシャーディングの一般的な方法には,レンジシャーディング,ハッシュシャーディング,一貫したハッシュアルゴリズム,仮想ハッシュスロットがあります.
レンジスライスは、データセットが順番に並んでいることを前提としており、順次近くにあるデータを置くことで、探索操作の良いサポートとなり得る。レンジスライスの欠点は、シーケンシャルな書き込みに直面したときにホットスポットが存在することです。例えば、ログ型の書き込みの場合、一般にログの順番は時間依存であり、時間は単調に増加するため、書き込みのホットスポットは常に最後のスライスに存在することになる。テーブルスキャンやインデックススキャンを定期的に行うリレーショナルデータベースでは、基本的に様々なシャーディング戦略が使われます。
異なるredisノードに異なるキーを分散させるためには、キーのハッシュを取得し、それをノード数に応じてモジュロするのが一般的ですが、これではノードを加減する必要があるときに、大量のキーがヒットしなくなり、かなりの高率になるという明らかな欠点があるので、一貫したハッシュという概念が導入されることになったのです。
コンシステント・ハッシングには、4つの重要な特徴があります。
- 均一性:バランスとも定義されるが、各ノードの資源を効率的に利用できるように、ハッシュの結果をできるだけすべてのノードに分散できることを意味する。
- 単調性。ハッシュの結果は、ノード数が変化したときに、新しいノードに再配布されないように分散された内容をできるだけ保護する必要がある。
- 分散と負荷。この2つは実はほとんど同じことで、つまり一貫性ハッシュアルゴリズムはキーハッシュの重複を可能な限り避けるべきである。
II. Redisのスライシング機構
しかし:一貫性のあるハッシュを使う代わりに、Redisクラスタではハッシュスロットの概念を導入しています。
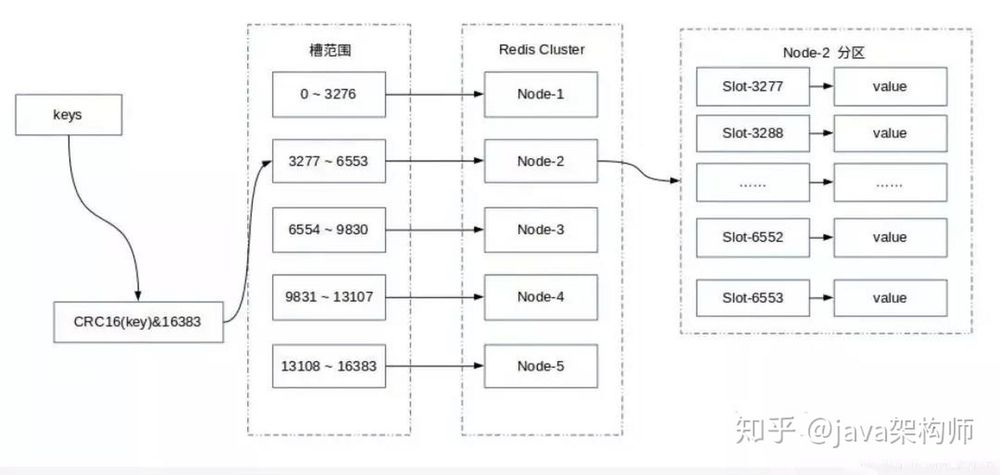
Redis Clusterは仮想ハッシュスロットパーティショニングを採用しており、すべてのキーはハッシュ関数に基づいて0から16383までの整数のスロットにマッピングされ、各キーはCRC16チェックサムによって16384をモジュロしてどのスロット(Slot)に配置するかを決定し、各ノードはスロットの一部とスロットにマッピングされているキーデータの管理を担当します。
計算式:スロット = CRC16(key) & 16383。
この構造により、ノードの追加や削除が容易になり、ノードの追加、削除、修正のいずれにおいても、クラスタが利用できない状態になることはない。ハッシュスロットを使用する利点は、ノードの追加や削除が簡単にできることです。
- ノードを追加する必要がある場合、いくつかのハッシュスロットを他のノードから新しいノードに移動するだけです。
- ノードを削除する必要がある場合、削除されたノードのハッシュスロットを他のノードに移動するだけです。
III. Redis仮想スロットパーティショニングの特徴
- データとノードの関係を切り離し、ノードのスケールアップやシュリンクの問題を簡素化します。
- ノード自身がスロットマッピングの関係を維持するため、クライアントやプロキシサービスがスロットパーティションのメタデータを維持する必要がありません。
- データルーティング、オンラインクラスタースケーリング、その他のシナリオのためのノード、スロット、キー間のマッピングクエリをサポートします。
IV. Redisのクラスタリングはどのようにスケールするか
Redisクラスタには、ノードのスケーリングとシュリンクの柔軟なオプションがあります。クラスターの外部サービスに影響を与えることなく、ノードを追加して拡張したり、一部のノードをオフラインにして縮小したりすることができます。スロットはRedisクラスタのデータ管理の基本単位であり、クラスタのスケーリングはすべてスロットとノード間のデータ移動に関係します。
1. クラスタのスケーリング
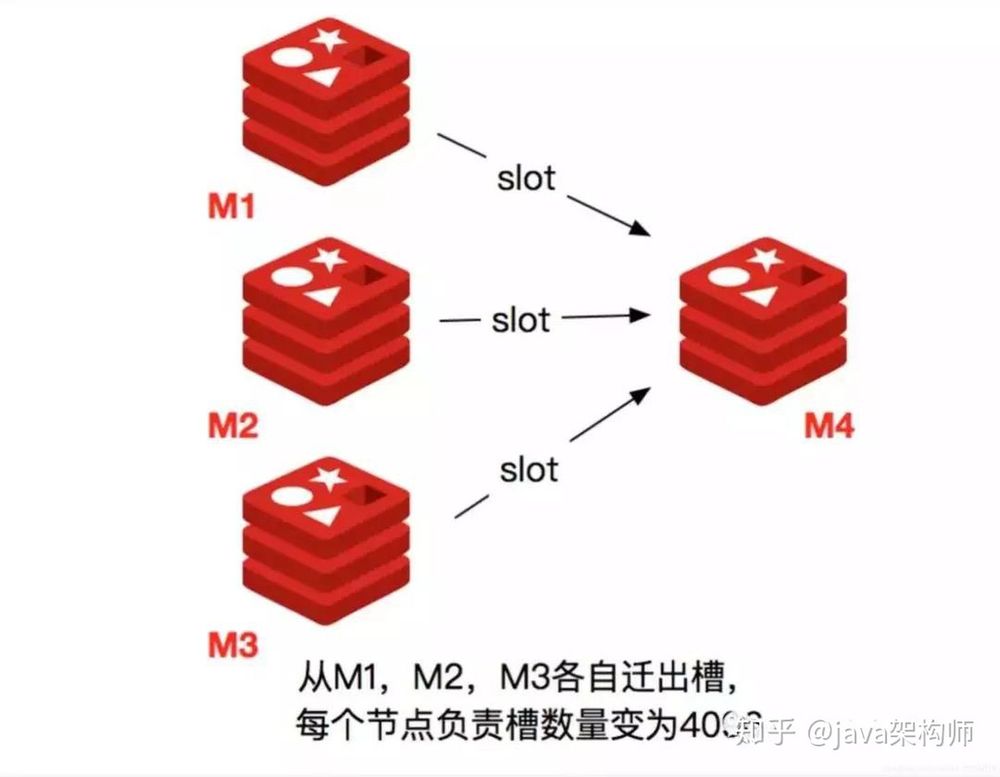
新しいRedisノードが稼働して既存のクラスタに参加する場合、そのスロットとデータをマイグレートする必要があります。最初のステップは、新しいノードのスロット移行計画を指定し、移行後に各ノードが同数のスロットを担当するようにし、それらのノードにデータが均等に分散されるようにすることです。
- まず、M4と表記されたRedisノードを起動します。
- cluster meetコマンドを使用して、新しいRedisノードをクラスタに追加します。新しいノードはマスターノード状態からスタートし、責任あるスロットを持たないため、読み取りまたは書き込み操作を受け付けることができません。
- M4ノードにcluster setslot { slot } importing { sourceNodeId }コマンドを送信し、ターゲットノードがスロットのデータをインポートできる状態にします。 >4) M1、M2、M3ノードであるソースノードに cluster setslot { slot } migrating { targetNodeId }コマンドを送信し、ソースノードがスロットからデータをマイグレーションする状態にします>5)。
- ソースノードがcluster getkeysinslot { slot }を実行します。{count }コマンドでスロット{ slot }に属するcount keysを取得し、ステップ>6を実行してキーデータを移行します。
- migrate { targetNodeIp} " " 0 { timeout } keys { key...をソースノードで実行します。} コマンドを実行すると、取得した鍵をパイプライン機構でターゲットノードに一括移行します> バルク移行版の migrate コマンドは Redis 3.0.6 以降で利用可能です。
- スロット配下のすべての鍵データがターゲットノードに移行されるまで、手順5と6を繰り返してください。
- cluster setslot { slot } node { targetNodeId } コマンドをクラスタ内のすべてのマスターノードに送信し、ターゲットノードへのスロット割り当てを通知します。スロットノードのマッピングの変更をタイムリーに伝搬させるために、すべてのマスターノードに送信された新しいノードを反復して、移行されるスロット実行を更新する必要があります>スロットノードのマッピングの変更をタイムリーに伝搬させるために、すべてのマスターノードに送信された新しいノードを反復して、移行されるスロット実行を更新する必要があります。
2. クラスター収縮
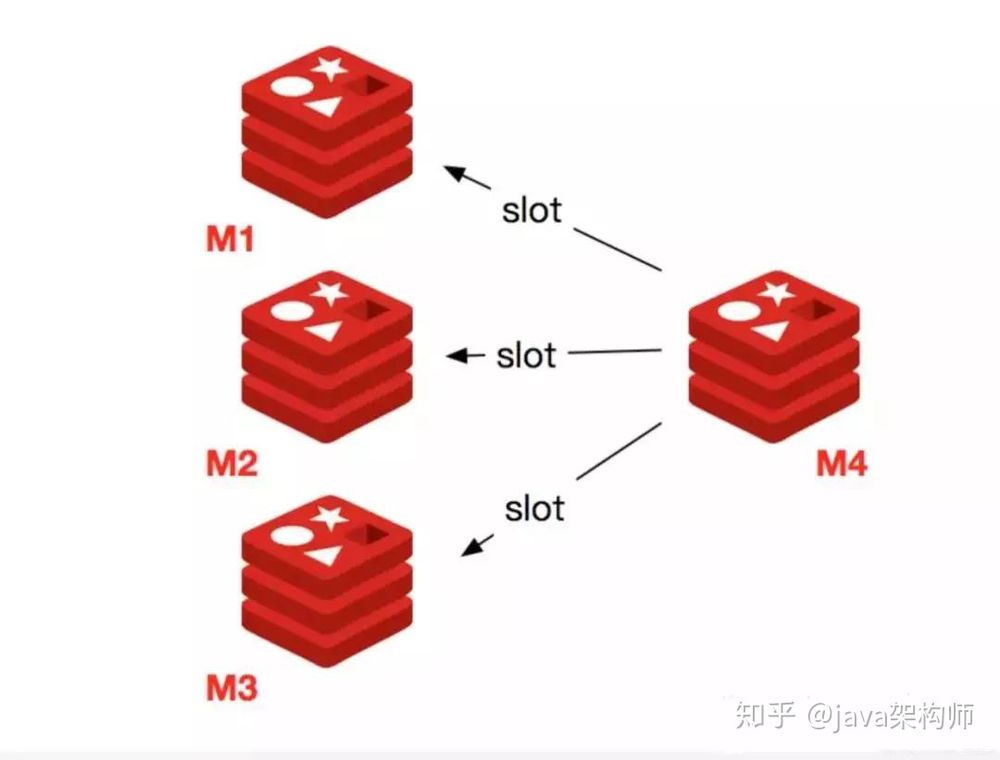
ノードの縮小とは、Redisノードをオフラインにすることで、全体の処理には以下の手順が必要です。
- まず、オフラインのノードに担当スロットがあるかどうかを確認し、ある場合はそのスロットを別のノードに移行して、ノードをオフラインにした後のクラスタースロット全体のノードマッピングの整合性を確保する必要があります。
- ダウンラインノードがスロットに責任を持たなくなったとき、またはノードから自身がいなくなったとき、クラスタ内の他のノードにダウンラインノードのことを忘れるように通知し、すべてのノードがノードの変更を忘れたときに正常にシャットダウンできるようにすることができます。
オフラインのノードでは、ノード自身が担当するスロットを他のノードに移行する必要があります。原理は、前回のノード拡張時の移行スロット処理と同じです。
スロットの移行後、クラスタ内のすべてのノードにオフラインになるノードのことを忘れるように通知する必要もあります。これは、他のノードがオフラインになるノードとGossipメッセージを交換しなくなることを意味します。 [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...]
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン