Spark SQLの全体的な実装ロジックの説明
1. sql文のモジュール式解析
クエリ文を書くとき、一般にselect部分、fromデータソース部分、where制限部分の3つの部分があり、これらはsqlで特定の名前を持っています。
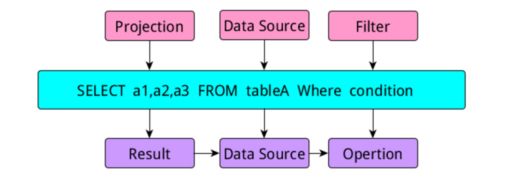
上記のようにsqlを書くと、論理パースによりprojectモジュール、DataSourceモジュール、Filterモジュールの3つに分割され、実行部分が生成されると、それらは:Resultモジュールと呼ばれるようになります。
DataSourceモジュールとOperationモジュールです。
そこでリレーショナルデータベースでは、実行のためのクエリ文を書き終えると、次の図のような処理が行われます。

実行プロセス全体は、クエリ -> 解析 -> バインド -> 最適化 -> 実行です。
1、SQLクエリ文を書いた後、SQLクエリエンジンは、まず我々のクエリ文を解析し、つまり、解析プロセスは、我々が書いたクエリ文、プロジェクト、データソースと解析のフィルタ3つの部分を分割することですこのように解析プロセスでは、論理解析ツリーを形成する、また私たちをチェックします解析の過程で、我々はまた、このデータテーブル、などが含まれていない、このような指標のフィールドが見つからないなどのエラーについては我々のSQL構文をチェックします。エラーが見つかった場合、解析は直ちに中止され、エラーが報告されます。解析が正常に終了すると、Bind処理に移行します。
2. Bind処理は、その言葉からもわかるように、バインド(結合)処理です。なぜバインドプロセスが必要なのでしょうか?この問いには、ソフトウェアの実装という観点で考える必要があります。このSQLクエリエンジンを実装するとしたら、どのようにすればよいのでしょうか。彼らの戦略は、まずsqlクエリ文を分割し、異なる部分を分割し、それをパースして論理的なパースツリーを形成します。そして、どこからデータを取り出すか、どのフィールドが必要か、どのロジックを実行するか、これらはすべてデータベースデータ辞書に格納されているので、実はバインド処理はパース処理の後に形成する論理パースです。 したがって、バインド処理は、実はパース処理の後に形成するロジックとデータベースデータ辞書の結合処理なのです。バインドでは、テーブルがどこにあるのか、どのフィールドが必要なのかなどをプログラムに知らせる実行ツリーが作成されます。
3. Bind処理完了後、データベースクエリーエンジンはいくつかのクエリー実行計画を提供し、クエリー実行計画に関するいくつかの統計情報を与えます。いくつかの実行計画が提供されるため、比較のメリットとデメリットがあり、データベースはこれらの実行計画の統計情報に基づき最適な実行計画を選択するので、このプロセスがOptimize処理となります。
4. 最適な実行計画を選択したら、最後にExecuteを実行することになりますが、これは解析した時とは異なる処理で、実行順序が分かっていると、後でsqlを書いて最適化する時に非常に助かります。クエリを実行した後、まずwhereの部分を実行し、次にデータソースのデータテーブルを探し、最後に最終結果であるselectの部分を生成しているのだそうです。実行順序は、operation->DataSource->Resultの順です。
上記の部分はSparkSQLとはあまり関係ありませんが、これを知っておくとSparkSQLを理解する上で役に立ちます。
2. SparkSQLフレームワークのアーキテクチャ
このフレームワークを明確に理解するためには、まず、なぜsparkSQLが必要なのかを把握する必要があります。個人的には、一般的にsqlを書けば直接解決できる問題にはsparkSQLを使わないことをお勧めしますし、意図的にsparkSQLを使いたい場合でも、必ずしも開発速度が速くなるわけではありません。sparkSQLの用途は、一般的にsqlで解決できない複雑なロジックを、プログラミング言語の利点を活かして解決することです。私たちのsparkSQLの使い方の一般的な流れは以下の通りです。
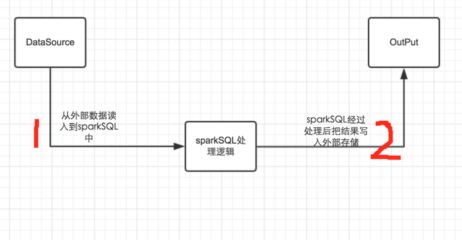
上記のように、一般的には、a.sparkSQLにデータを読み込み、sparkSQLがデータ処理やアルゴリズムの実装を行い、処理後のデータを適切な出力ソースに出力する、という2つのパートに分かれます。
1. ここでも、開発を依頼されたら何をすべきか、何を考えなければならないかという観点で考えています。
a. まず、データソースはいくつあり、どのようなデータソースからデータを読み込む可能性があるのか、ということです。現在sparkSQLは、hiveデータウェアハウス、jsonファイル、.txt、orcファイルなど多くのデータソースをサポートしており、さらにリレーショナルデータベースからデータを取得するjdbcもサポートするようになりました。これは非常に強力です。
b. もう一つ考えるべきことは、データ型をどのようにマッピングするかということです。データベースのテーブルからデータを読み込むとき、私たちが定義したテーブル構造のフィールドの型と、scalaのようなプログラミング言語のデータ型のマッピングはどうなっているのでしょうか?この問題を解決するために、sparkSQLではデータテーブルのフィールドの型とプログラミング言語のデータ型の間のマッピングを実装する方法があるのです。これについては後で詳しく説明しますが、まずは問題があることだけを理解してください。
c. データは入手できたので、sparkSQLでどのように整理すればよいのか、どのようなデータ構造が必要なのか、どのような操作が可能なのか。DataFrameのデータ構造は、データが行単位で格納されており、各行のデータがどのフィールドに属するかを記録した、データベースのテーブル構造に相当するスキーマが存在します。
d. データが完成したら、それをどこかに置いて、どのような形式に対応するのかを切り出す必要がありますが、これはaとbが解決しなければならない問題と同じです。
2. 上記の問題に対する sparkSQL の実装ロジックも、上の図から既に明らかなように、大きく2つのフェーズに分かれており、それぞれが実装すべき特定のクラスに対応しています。
a. 最初のフェーズでは、これらの問題を解決するために sparkSQL には 2 つのクラスが存在します。HiveContext、SQLContext、hiveContextはSQLContextのすべてのメソッドを継承しつつ、それを拡張しています。hiveとmysqlのクエリには違いがあることがわかっているので、HiveContextはhiveデータウェアハウスからの読み込みのみを扱い、SQLContextはsparkSQLがサポートできる残りのすべてのデータソースを扱えるようになっています。この 2 つのクラスの粒度は、データへの読み書きと、データの読み込み、テーブルのキャッシュ、キャッシュの解放、テーブルの登録、登録したテーブルの削除、テーブル構造の返却など、テーブルレベルの操作に限定されます。
b. sparkSQLは、DataFrameで提供されるメソッドを使用して、読み込んだデータを処理します。これは、sparkSQLにデータを読み込むとき、そのデータはDataFrame型であるためです。また、データはRowにしたがって格納されます。その中でもDataFrameは多くの便利なメソッドを提供しています。それについては後ほど詳しく説明します。
c. spark1.6以降、DataFrameに似たデータ構造であるDatasetが追加されました。このデータ構造を追加した目的は、DataFrameはRowとして格納されたデータしか扱えず、DataFrameで提供されるメソッドしか使えないという弱点があるからです。Datasetを実装した目的は、sparkSQLのデータをRDDのように操作できるようにするためです。
d. 他にもいくつかクラスがありますが、今のところsparkSQLのメインは上記3つで、他のクラスは後で遭遇した時に徐々に解明していく予定です。
3. sparkSQLのhiveContextとSQLContextの仕組み
hiveContextとSQLContextは、実は最初に話したsql文を解析するモジュールと同じ論理処理で、この部分についてはウェブ上でたくさん語られているので、そのまま貼り付けてコピーしてください!。
sqlContextの全処理は以下の図の通りです。
1. SQL文はSqlParseによってUnresolvedLogicalPlanにパースされます。
2. アナライザーとバインディング用データ辞書(カタログ)を組み合わせて使用し、resolvedLogicalPlanを生成する。
[...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...] [...]
関連
-
SQL Server2017では、IPをサーバー名としてサーバーに接続します。
-
SQLの書き方--行ごとの比較
-
Filestreamの簡単な使い方まとめ
-
リレーショナルデータベースと非リレーショナルデータベースの紹介
-
mybatis動的SQLの共通シナリオのまとめ
-
SQLServerのエラーです。15404, unable to get information about Windows NT group/user WIN-8IVSNAQS8T7Administrator
-
SQLでのmod()関数の余りの使用法
-
SQL クエリ結果カラムのカンマ区切り文字列へのステッチング法
-
SQL SERVERオープンCDC実践講座詳細
-
sql serverで最初の1000行のデータを削除する方法の例
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
SQL Server 2019 データベースバックアップ&リストアスクリプト(一括バックアップ)
-
SQLインジェクションとその防止、マイベイトの基本的な役割について
-
あるユーザーの連続ログイン日数を求めるSQLクエリ
-
DataGrip Formatting SQLの実装(カスタムSqlフォーマット)
-
MySQLスレーブ遅延1列外部キーチェックとセルフインクリメントロック
-
NavicatはSQL Serverのデータに接続します。エラー08001に対する完璧な解決策 - Named Pipeline Provider
-
SQL文におけるJOINの利用シーンの分析
-
SQL SERVERのコミット・トランザクションのロールバック機構
-
そのPHP環境の普遍的なパスワードのSQLインジェクションの脆弱性と防御手段
-
データベース毎日練習問題、毎日少しづつ進歩(1)