2021年版Redisインタビューの質問(継続更新中)
目次
1 redis の基礎知識
redis のデータ型は何ですか
Redisは、string(文字列)、list(リスト)、set(セット)、hash(ハッシュ)、zset(順序付きセット)という5つの基本データ構造を持っています。
Redisのリストは、Java言語のLinkedListに相当するもので、配列ではなくリンクリストである点に注意が必要です。つまり、リストの挿入と削除は非常に高速で、時間複雑度はO(1)ですが、インデックスの位置決めは遅く、時間複雑度はO(n)で、これは非常に驚くべきことです。リストが最後の要素をポップした後、データ構造は自動的に削除され、メモリが再利用されます。
Redisのハッシュは、Java言語のHashMapに相当するもので、順序のない辞書である。内部実装はJavaのHashMapと同じで、配列+リンクテーブルの2次元構造になっています。1次元のハッシュの配列位置がぶつかると、ぶつかった要素を連鎖表を使って連結する。
Redisコレクションは、Java言語のHashSetに相当し、内部のKey-Valueペアは順不同かつ一意である。その内部実装は特殊な辞書と同等であり、辞書内のすべての値は単一の値NULLである。コレクション内の最後の要素が削除されると、データ構造は自動的に削除され、メモリが再利用される。
zsetは、JavaのSortedSetとHashMapを組み合わせたようなもので、内部値の一意性を保証するセットであり、各値にその値のソート重みを表すスコアを割り当てることができる。
なぜredisは高速に
i. リクエストの大部分は純粋にインメモリ操作である(非常に速い)
ii. シングルスレッドで、不要なコンテキストスイッチや競合状態を回避できる
iii. ノンブロッキング IO - IO マルチプレクシング
2 Redisに含まれる5つのデータ構造
文字列
redisはC言語で開発されていますが、C言語には文字列の型がなく、ポインタかシンボルの配列の形でしか文字列を表現できないため、redisではSDS(Simple Dynamic String)を基礎実装として設計しています。
SDSオブジェクトを定義します。このオブジェクトには3つのプロパティがあります。
- len bufに既に格納されている長さ(この文字列の実際の長さを示す)
- 空きbufの未使用バッファの長さ
- 実際の文字列データが格納されるbuf[]を指定します。
つまり、文字列の長さを取るための時間計算量はO(1)なのです。また、buf[]には、C言語の標準的な文字列ライブラリ関数のうち、末尾が" \0" のものが残っており、C言語で直接使用することができます。
領域割り当ての原則:lenがIMB(1024*1024)未満の場合、文字列割り当て領域のサイズを元の2倍に増やし、lenが1M以上の場合、割り当てごとに1Mの領域を追加で割り当てます。
これより、以下のプロパティを導き出すことができる。
- Redisが文字用に領域を確保する回数は、文字列の長さN以下です。一方、C言語の本来の割り当て原則はNでなければなりません。割り当て回数を減らすと、自動的に解放されないメモリ領域が増える代わりに、追記速度が向上します。
- バイナリセーフ
- 文字列の長さを効率的に計算 (時間計算量 O(1))
- 文字列の追加操作を効率的に行える。
リスト
redisはキーテーブルを構造的にサポートしているため、キーバリューストレージの世界ではユニークな存在です。リスト構造は複数の文字列を順序よく格納することができ、次のようなコマンドがあります: lpush lpop rpush rpop, and so on. バージョン3.2以前では、リストはziplistとlinkedlistを使って実装されていました。これらの古いバージョンでは、以下の両方の条件を満たす場合、リストオブジェクトはziplistを使ってエンコードされていました。
- リストオブジェクトが保存するすべての文字列要素の長さが64バイト未満である。
- リストオブジェクトの保存要素数が512未満である
いずれかの条件を満たさない場合、リンクリストを用いたトランスコーディングが行われる。
そして、バージョン3.2以降では、クイックリストデータ構造が再登場した。基となるリストはquicklistで実装され、ziplistとlinkedlistの長所を併せ持っている。このデータ構造の本来の説明によると、[A doubly linked list of ziplists]とは、ziplistで構成された双方向リンクリストを意味します。では、この2つのデータ構造はどのように組み合わされるのでしょうか。
ジップリストの構造
テーブルヘッダとN個のエントリノードからなる連続したメモリブロックと、圧縮されたリストの末尾にあるzlend識別子からなる。そして、主に整数や比較的短い文字列を格納するための一連のエンコーディング規則によって、メモリ使用率を向上させている。要素の挿入と削除の際には、どちらもメモリの拡大・縮小と部分的なデータ移動操作が必要であり、非効率な更新を引き起こす可能性があることがわかる。
ziplistの構造については、こちらの記事で詳しく解説しています。
https://blog.csdn.net/yellowriver007/article/details/79021049
リンクリストの構造
双方向リンクリストを意味し、通常のリンクリストの定義と同じで、各エントリには前方ポインタと後方ポインタがあり、要素を挿入または削除するときは、この要素の前方と後方のポインタに対してのみ操作すればよい。そのため、挿入や削除の効率は非常に高い。しかし、問い合わせの効率はO(n)[nは要素の数]である。
上記の2つのデータ構造を理解したところで、"ziplist"の意味について見てみましょう。クイックリストノードはデータの断片を保持します。要約すると
- 全体のクイックリストは双方向リンクテーブル構造で、通常のチェーンテーブル操作と同様に、挿入と削除は効率的だが、クエリー効率はO(n)である。しかし、このような連鎖表の両端の要素にアクセスする時間計算量はO(1)である。そこで、リストに対する操作のほとんどはポーリングとプッシュである。
- 各クイックリストノードはジップリストであり、圧縮リストの性質を持つ。
セット(set)
redisのコレクションとリストの違いは、リストは同じ文字列を複数格納できるのに対し、コレクションは格納する文字列がそれぞれ異なることを保証するためにハッシュテーブルを使用し(これらのハッシュテーブルはキーだけを持ち、キーに関連する値はありません)、redisのコレクションは順不同である点です。もう一つのコレクションとして、同じ型の整数を保存するための順序付きコレクションであるintsetが存在する場合もある。整数の種類はint16_t, int32_t, int64_tの3種類である。ルックアップの時間計算量はO(logN)であるが、挿入時にはアップグレードが伴う場合がある(例:元の集合はint16_t、挿入時にはint32_tの整数が要素ごとにint32_tにアップグレード)この時間は、メモリに再割り当てされることになる。したがって、この時点での時間複雑度はO(N)レベルである。注意:intsetはアップグレードのみサポートし、ダウングレードはサポートしていません。
intsetはまた、redis.confの設定パラメータset-max-intset-entriesのデフォルトが512で、エントリ数がこの値より少ない場合、メモリを節約するためにREDIS_ENCODING_INTSET型として符号化できることを示しています。それ以外の場合は、dictとして保存されます。
ハッシュ
ハッシュの基礎となるデータ構造は、2つの方法で実装されています。
-
1つは、前述したziplistです。格納されたデータが設定された閾値を超えると、hashtable構造に切り替わるようになっている。この変換はよりパフォーマンスを要するので、可能であれば避けるべきである。この構造体は、以下の両方の条件を満たす場合にのみ使用される。
- キー数がhash-max-ziplist-entries(デフォルト512)未満の場合
- すべての値がhash-max-ziplist-valueより小さい場合(デフォルト64)
- もう一つはhashtableである。この構造は時間計算量がO(1)であるが、より多くのメモリ空間を消費する。
zset (順序付きセット)
順序付きセットはハッシュと同様,キーと値のペアを保存するために使われます.順序付きセットのキーはメンバーと呼ばれ,それぞれのメンバーは他のメンバーとは異なります.順序付きセットの値はスコアと呼ばれ,スコアは浮動小数点数でなければならない.順序付きセットはredisで唯一、メンバー(これはハッシュと同じです)とスコアの両方とその順序に基づいて要素にアクセスできる構造です。また、2つの方法で保存することができます。
- はジップリスト構造体です。
上記のハッシュのジップリストと同様に、メンバーとスコアが順番に格納され、スコアの順に並べられる
- もうひとつは、skiplistとdictを組み合わせたものです。
skiplistは、順序付きコレクションの高速検索のためのジャンプテーブル構造で、ほとんどの場合、バランスツリーと同程度の効率ですが、バランスツリーよりも実装が簡単です。 redis author has modified the normal jump table by adding spantailtailbackward pointers and repeatable values for scores to enable sorting functionality and reverse The authors of redis modified normal jump table by adding spantailtailbackward pointers and repeatable score values to enable sorting and reverse traversal.The redis作者は、ソートや逆引きを行うために、通常のジャンプテーブルにスパンテイルバックワードポインタと反復可能なスコア値を追加しました。
一般的なジャンプテーブルの実装は、主に以下の部分から構成される。
-
Table header (head): ヘッドノードを指します。 -
Table tail (tail): テールノードを指します。 -
node (node): 実際に保存された要素ノード。各ノードは複数のレイヤーを持つことができ、レイヤー数はこのノードが作成されるときにランダムに生成される値であり、各レイヤーはそれに続く何らかのノードへのポインターである。 -
Layer (level): 現在のテーブルのノードの最大レベル数 -
Length (length): ノードの数です。
ジャンプテーブルの走査は常に高いレベルから始まり、要素の値の範囲が狭くなるにつれてゆっくりと低いレベルへと減少していきます。
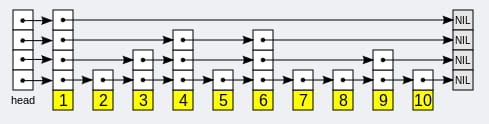
ジャンプテーブルの実装原理は、以下のサイトに掲載されています。 https://blog.csdn.net/Acceptedxukai/article/details/17333673
前述したように、順序付きリストはskiplistとdictの組み合わせで実装されています。skiplistは順序性とアクセス検索性能を保証するために用いられ、dictは要素情報を格納するために用いられ、dictのアクセス時間複雑度はO(1)とされています。
3 Redis の永続性
Redisの永続化機構
RDBの永続性
RDBパーシステンスはRedisのデフォルトのパーシステンス方法であり、手動および自動で起動されます。
AOFパーシステンス
AOF (Append-Only-File) persistence は、データベースの状態を変更するすべてのコマンドを記録し、AOF ファイルにアペンドという形で追加するプロセスである。次にサーバーを起動したときに、AOFファイルに保存されているコマンドを読み込んで実行することで、サーバーがシャットダウンする前にデータベースの状態を復元することができます。
RDB、AOFのハイブリッド永続化
Redisはバージョン4.0以降、RDBとAOFのハイブリッド永続化スキームをサポートしています。まずRDBが定期的にメモリ内スナップショットのバックアップを完了し、次にAOFが2つのRDB間のデータバックアップを完了し、この2つの部分を合わせて永続化ファイルを構成します。このソリューションの利点は、RDBの読み込みが速く、バックアップファイルが小さく、AOFはできるだけデータを失わないという特性を十分に生かすことです。デメリットは、ハイブリッドパーシステンスを有効にすると、4.0以前のバージョンではパーシステンスファイルが認識されない、最初の部分がRDB形式であるため可読性が低いなど、互換性の低さである。
Redis永続化スキームに関する推奨事項
Redisがデータベースクエリの後にデータをキャッシュするような、キャッシュサーバとしてのみ使用される場合、キャッシュサービスに失敗しても、再度データベースから取得することで回復できるため、永続性は無視することができる。
もし、高いレベルのデータ保証を提供したいのであれば、両方のタイプの永続化を使用することが推奨されます。災害による数分のデータ損失を許容できるのであれば、RDBのみを使用すればよいでしょう。
一般的な設計思想としては、永続化する際のパフォーマンスへの影響を補うために、マスター・スレーブ型のレプリケーション機構を使用することが挙げられます。つまり、マスターではRDBもAOFも行わず、マスターでの読み書きのパフォーマンスを確保し、スレーブではRDBとAOF(バージョン4.0以上ではハイブリッド永続化方式)の両方をオンにしてデータセキュリティを確保した永続化を行うのです。
Redisパーシステンスソリューションの長所と短所
RDBパーシステンス
長所 RDBファイルはコンパクトで小さく、ネットワーク転送が高速で、フルレプリケーションに適している;AOFよりリカバリーがはるかに速い。もちろん、AOFに対するRDBの最も重要な利点の1つは、パフォーマンスへの影響が比較的小さいことです。
デメリット RDBファイルの致命的な欠点は、データスナップショット永続化のため、必ずしもリアルタイム永続化ができないことで、データの重要性が増している今日、大量のデータロスは何度も許容されないため、AOF永続化が主流になっている。また、RDBファイルは特定のフォーマットを満たす必要があり、互換性が低い(例えば、古いバージョンのRedisと新しいバージョンのRDBファイルの互換性はない)。
AOFパーシステンス
RDB永続化とは対照的に、AOFは第2レベルの永続化サポートと互換性という長所と、ファイルサイズが大きく、回復に時間がかかり、パフォーマンスに影響が大きいという短所がある。
4 キャッシュの侵入、キャッシュの破壊、キャッシュ・アバランシェの解決策
キャッシュ・ペネトレーション
存在してはならないデータを問い合わせ、そのデータがストレージ層から利用できない場合はキャッシュに書き込まないことを指し、この場合、この存在しないデータがリクエストごとにDBに送られ、DBがハングする可能性がある。
解決策
i. クエリがNULLデータを返しても、このNULL結果はキャッシュされますが、有効期限は短くなります。
ii. ブルームフィルタ。存在してはならないデータがこのビットマップによってブロックされるように、すべての可能なデータを十分な大きさのビットマップにハッシュ化し、DBへのクエリーを回避する。
キャッシュの内訳
有効期限が設定されている鍵の場合、ある時点でキャッシュが切れると、その時点でその鍵に対する同時リクエストが大量に発生し、これらのリクエストはキャッシュが切れたことを知り、一般的にバックエンドのDBからデータをロードしてキャッシュに戻すので、大量の同時リクエストで一瞬にしてDBを圧迫してしまうことがあるのだそうです。
解決策
i. ムテックスロックを使用する。キャッシュに失敗した場合、すぐに db をロードするのではなく、Redis の setnx のような mutex ロックを使用して db をロードし、操作が正常に戻ったときにキャッシュをセットバックし、それ以外の場合は get cache メソッドを再試行します。
ii Never expire: 物理的には期限切れにならないが、論理的には期限切れになる(バックグラウンドの非同期スレッドでフラッシュする)。
キャッシュなだれ
キャッシュの設定に同じ有効期限を使用したため、ある時点でキャッシュが同時に失効し、リクエストが全てDBに転送され、雪崩を打って一瞬で過負荷になる。キャッシュ・ブレイクダウンとの違い:雪崩は多数のキー、ブレイクダウンは特定のキーのキャッシュ。
解決策
キャッシュの有効期限を分散させる。例えば、本来の有効期限に1~5分のランダムな値を加えることで、各キャッシュの有効期限の繰り返し率が下がり、まとめて有効期限切れイベントを発生させることが難しくなるようにする。
5 Redisのクラスタリングモデル
マスター・スレーブ レプリケーション
いつ スレーブデータベースが起動すると、マスターデータベースに同期コマンドを送信し、マスターデータベースは同期を受信して、バックグラウンドでスナップショットrdbの保存を開始します。 スナップショット保存期間中に受信したコマンドはキャッシュされ、スナップショットが完了すると、マスターデータベースはスナップショットとキャッシュされたコマンドを一括してslave**に送ります。レプリケーションの初期化が終了します。その後、マスターは受信したコマンドをすべてスレーブに同期して送信します。切断と再接続があった場合、2.8以降のバージョンでは、切断時のコマンドを再データベースに渡します。インクリメンタルレプリケーション
マスタースレーブレプリケーションは楽観的なレプリケーションで、クライアントがマスターに書き込み実行を送ると、マスターは実行後すぐにクライアントに結果を返し、非同期にスレーブにコマンドを送るのでパフォーマンスに影響はありません。また、書き込みが可能になるまでに同期させるスレーブマスタの最小数を設定することも可能です。ハードディスクレスレプリケーション。ハードディスクの効率が悪いと、レプリケーションのパフォーマンスに影響が出ます。2.8以降では、ハードディスクレスレプリケーション、 repl-diskless-sync yesを設定することができます。
セントリーモード
[外部リンクの画像ダンプに失敗しました。ソースサイトに盗難防止用のチェーン機構がある可能性があります。画像を保存して直接アップロードすることをお勧めします(img-Hzcc1bJo-1613794914158) (https://s3-us-west-2.amazonaws.com/secure.notion-static.com/ 3e8c3ce5-a43d-45f0-a384-90ecc42dbaff/Untitled.png) ]。
センチネルの役割
1. redisマスターとスレーブデータベースが正しく動作しているか監視する
2. マスターに障害が発生した場合、スレーブデータベースをマスターデータベースに自動変換する。
Sentinelのコアとなる知識
1. センチネルは堅牢性を確保するために、少なくとも3つのインスタンスが必要です。
2. Sentinel + redis のマスター・スレーブ展開のアーキテクチャは データ損失ゼロを保証するものではありません Redisクラスタの高可用性を保証するだけです。
3. Sentinel + redis master-slaveのような複雑なデプロイメントアーキテクチャの場合、テスト環境と本番環境の両方で十分なテストとリハーサルを行うようにしてください。
4. センチネルがシステムを監視するように設定する場合 プライマリデータベースを監視するように設定するだけでよい セントリーでは、マスターデータベースを複製するすべてのスレーブデータベースを自動的に検出します。
6 Redis の分散ロック
Redisの分散ロックを使ったことがありますか、そしてそれはどのようなものですか?
まずsetnxでロックを奪い合い、それを掴み、expireでロックに有効期限を付けて解除し忘れを防止するのです。
setnx の後に expire が実行される前にプロセスがクラッシュしたり、メンテナンスのために再起動したりすると、ロックは決して解放されませんので、set ディレクティブを使って setnx と expire をひとつのディレクティブにまとめてください。
レッドロック
Redisで複数のマスターインスタンスを使用してロックを取得する場合、ほとんどのインスタンスがロックを取得した場合にのみ、取得が成功したとみなされます。具体的なレッドロックのアルゴリズムは、以下の5つのステップに分かれます。
- 現在時刻(ミリ秒単位)を取得する。
- 同じキーとランダムな値を使って、N個のノードにロックを要求する。ここでロックを取得しようとする時間は、いくつかの masterDown を防ぐために、ロックのタイムアウト時間よりもずっと短くする必要があり、我々はまだ常にロックを取得し、長すぎるためにブロックされます。
- ほとんどのノードでロックが取得され、かつ取得時間の合計がロックタイムアウト未満である場合にのみ、ロックの取得が成功したとみなされます。
- ロックが正常に取得された場合、ロックタイムアウトは最初のロックタイムアウトにロック取得に要した合計時間を加えたものになります。
- ロック取得に成功したノード数が半分を超えなかったか、ロック取得に要した時間がロック解除時間を超えたためにロック取得に失敗した場合、キーが設定されたマスターからキーが削除されます。
7いくつかの質問
メモリ消去の仕組み
redisのメモリフェーズアウト機構は以下のようなものです。
- noeviction。新しい書き込みに十分なメモリがない場合、新しい書き込み操作はエラーを報告します。これは一般的に誰も使いません。あまりにもみっともないだけです。
- allkeys-lru: 新しい書き込みのための十分なメモリがない場合、最も最近使われたキーをキースペースから削除します(これは最も一般的に使用されます)。
- allkeys-random。新しい書き込みのための十分なメモリがないとき、鍵空間からランダムな鍵を削除する。これは一般に誰も使わないが、なぜランダムでなければならないのか?
- volatile-lru: 新しい書き込みのための十分なメモリがない場合、有効期限が設定された鍵空間から最も最近使用された鍵を削除します(これは一般的に適切ではありません)。
- volatile-random。新しい書き込みのために十分なメモリがないとき、有効期限が設定された鍵空間からランダムな鍵を削除します。
- volatile-ttl: 新しい書き込みのために十分なメモリがない場合、有効期限が設定された鍵空間から、有効期限が早い鍵を先に削除します。
RedisとMysqlのデータが一致しない場合の対処法
遅延二重削除戦略の使用
- 2番目の削除redis。キャッシュされたredisが削除された場合、ライブラリMySQLを書き込む時間がないうちに、別のスレッドが読みにきて、キャッシュが空だとわかり、データベースにデータを読みに行き、この時点でキャッシュが汚れている。
- また、redisを最初に削除するスレッドは、ライブラリが先に書き込まれ、ライブラリを書き込んだスレッドがキャッシュを削除する前にダウンし、キャッシュを削除しない場合、データの整合性がとれなくなります。
public void use(String key, Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(800);
redis.delKey(key);
}
(1)まずキャッシュをなくす
(2) その後、データベースを書き込む(この2つのステップはオリジナルと同じです)
(3) 800msの間Hibernateし、再びキャッシュをフェイズアウトさせる。
そうすることで、800msで作成されたキャッシュから、再びダーティなデータが削除されます。
Redisのパフォーマンスに関するよくある問題と解決策。
i. マスターは、より良いRDBのメモリスナップショットやAOFログファイルなどの永続化作業をしない、(マスターは、メモリスナップショット、コマンドディスパッチrdbSave関数を保存すると、スナップショットがパフォーマンスへの影響は比較的大きいときに、メインスレッドの作業をブロックします非常に大きく、断続的にサービスを中断するので、マスターは、メモリスナップショットを書いていない方が良い、AOFファイルも(大規模はマスター再生の回復速度に影響を与えます)。
ii. データが重要である場合、スレーブはAOFを有効にしてデータをバックアップし、1秒に1回同期するようにポリシーを設定する必要があります。
iii. マスターとスレーブのレプリケーションの速度と接続の安定性のために、マスターとスレーブは同じLAN上にあるのがベストです。
iv. ストレスを受けたマスターにスレーブを追加することはなるべく避けてください。
v. マスターとスレーブのレプリケーションにグラフィカルな構造を使用する代わりに、より安定した一方向のチェーンテーブル構造、すなわち、マスター <- スレーブ1 <- スレーブ2 <- スレーブ3・・・を使用します。この構造は単一障害点問題の解決やスレーブからマスターへの置き換えを実現するのに都合が良いです。マスターがハングアップしても、すぐにSlave1をマスターとして有効化し、残りは変更しないようにすることができます。
mySQLに2000wのデータがあり、redisには20wしかない、redisにあるすべてのデータがホットであることを確認する方法
volatile-lru
: 有効期限が設定されたデータセット (server.db[i].expires) から、最も最近使用されたデータの陳腐化を選択します。
volatile-ttl
: 有効期限が設定されたデータセット (server.db[i].expires) から、有効期限切れにするデータを選択します。
volatile-random
: データセット (server.db[i].expires) から有効期限が設定された任意のデータを選択します。
allkeys-lru
: データセットから最も最近使われたデータを取り出す(server.db[i].dict)
allkeys-random
: データセット (server.db[i].dict) から任意のデータを選択し、削除する。
no-enviction (eviction)
: 立ち入り禁止データ
volatileとallkeysは有効期限を設定したデータセットからデータを消去するか、データセット全体から消去するかを指定し、lru、ttl、randomは3種類の消去方法、さらに消去しないnever-recycle方法を指定しています。
ポリシールールの使用
1. データがべき乗分布を示している場合、つまり、データの一部が高い頻度でアクセスされ、一部が低い頻度でアクセスされる場合、allkeys-lru
2. 2. データが均等に分布している場合、すなわち、すべてのデータが同じ頻度でアクセスされる場合、allkeys-random を使用します。
Redisには1億個のキーがあり、そのうちの10Wは既知の固定プレフィックスで始まっています。
keysコマンドで、指定したパターンに該当するキーのリストを一掃する。続いて、相手が質問する。このredisがオンラインビジネスを提供しているとしたら、keys命令を使うことの何が問題なのでしょうか?この場合、redisの大きな特徴の一つであるシングルスレッドであることに答えなければなりません。keysディレクティブはスレッドを一定時間ブロックし、ディレクティブが実行されてサービスが再開できるまでオンラインサービスを停止させます。このとき、指定したスキーマのキー一覧をブロックせずに抽出できるscan命令を使えばよいのですが、一定の確率で繰り返しが発生するので、クライアント側で一度重複排除を行うことができますが、全体としてはkeys命令を直接使うよりも時間がかかることになります。
プロジェクトはRedisトランザクションを使用しますか
Redis Clusterアーキテクチャを採用しており、異なるRedisノードに異なるキーが割り当てられる可能性があり、その場合Redisトランザクションの仕組みは有効ではありません。次に、Redisトランザクションはロールバック操作をサポートしないので、基本的に必要ありません!
ブルームフィルタ
5分でわかるブルームフィルタ、10億ドルのデータフィルタリングアルゴリズムにふさわしい
Redisテーブルホッピングの原理
テーブルスキップの時間的複雑性、実装原理、適用シナリオを徹底解説
一貫したハッシュアルゴリズム
8 参考資料
全部は覚えていないかもしれないので、引き落とした場合は後で追加するようにご指摘ください
https://blog.csdn.net/bird73/article/details/79792548
関連
-
この操作を行うには、少なくとも1つのSUPER権限が必要です。
-
親行が削除または更新できない: 外部キー制約に失敗 解決策
-
MySQLデータベースのクエリ機能を使用する際に、グループ関数の使用が無効である問題の解決方法
-
EF Exception Inquiry (エンティティオブジェクトは、IEntityChangeTrackerの複数のインスタンスから参照できません。)...
-
IEntityChangeTracker の複数のインスタンスからエンティティオブジェクトを参照できない場合の対処法
-
SQL SERVER データベース SELECT INTO および INSERT INTO の使用法(テンポラリテーブルへのデータ挿入を含む)
-
ORA-65096 無効な共通ユーザー名またはロール名
-
DB2 SQL エラーの解決法。sqlcode=-420, sqlstate=22018
-
Linuxでmysql-5.7.30をインストールするための詳細な手順
-
AttributeError: 'function' オブジェクトには 'cursor' という属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
(NTDLL.DLL): 0xC0000005: アクセス違反 - 解決
-
unixODBC:データソース名が見つからない、デフォルトドライバが指定されていないに関する質問
-
解決策: テーブルの定義が正しくありません。
-
mongodbの更新操作の更新
-
MongoDBコマンド
-
は、GROUP BY句に含まれるか、集約関数で使用される必要があります。
-
Oracleデータベースの挿入データエラーです。ORA-06550
-
ORA-06550 "の解決策。1 行目、7 列目"
-
PDOデータベース接続エラー。SQLSTATE[HY000] [2002] そのようなファイルやディレクトリはありません。
-
MySqlエラー解析'where節'の未知の列'xxx'