Goにおける文字列と[]byteの効率的な相互変換の例
前置き
データのシリアライズやデシリアライズの操作にgoを使う場合、文字列とバイト配列の間の変換を伴うことが多いかもしれません。例えば
if str, err := json.Marshal(from); err ! = nil {
panic(err)
} else {
return string(str)
}
jsonは[]byte型にシリアライズされており、string型に変換する必要があります。データ量が少ないときは型間の変換のオーバーヘッドは無視できますが、データ量が多くなるとパフォーマンスのボトルネックになることがあり、効率的な変換方法を使うことでこのオーバーヘッドを軽減することができます
データ構造
変換方法を理解する前に、基礎となるデータ構造を理解する必要があります
この記事は、go 1.13.12に基づいています。
の文字列を使用します。
type stringStruct struct {
str unsafe.Pointer
len int
len int}
のスライスです。
type slice struct {
array unsafe.
len int
cap int
cap int}
sliceの構造と比較して、stringには容量を示すcapフィールドがないため、stringの探索に組み込みのcap()関数を使用することができません。go では文字列は (他の多くの言語と同様に) 不変であるように設計されており、slice のように追加することができないため、基礎となる配列の容量を超えたかどうかを判断し、それを拡張するかどうかを決めるための cap フィールドは必要ありません。
len属性だけが、for-rangeのような読み込み操作に影響を与えません。for-range操作は、lenに基づいてループから飛び出すかどうかを判断するだけだからです。
では、なぜ文字列はimmutableに設定する必要があるのでしょうか。それは、文字列の基礎となる配列が変化しないようにするためです。
例えば、マップのキーにstringを使用する場合、基になる文字の配列が変わると計算されるハッシュ値も変わってしまい、マップから探すときに前の値が見つからなくなるので、その不滅性がそれを防ぎ、マップのキーとしてstringは適しています。また、不変性という特徴は、データのスレッドセーフを保証するものでもある
一般的な実装
文字列の不変性には多くの利点がありますが、その不変性を維持するために、文字列とバイト配列のインターリーブが、通常、データコピーという手段で実現されます。
var a string = "hello world"
var b []byte = []byte(a) // string to []byte
a = string(b) // []byte to string
これは実装が簡単ですが、基礎となるデータの複製によって実現されており、コンパイル時にそれぞれ slicebytetostring と stringtoslicebyte への関数呼び出しに変換されます。
文字列から[]バイト
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf ! = nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
// request memory
b = rawbyteslice(len(s))
}
// Copy the data
copy(b, s)
return b
}
スライスを要求するために buf を使うか rawbyteslice を呼ぶかは、戻り値がヒープにエスケープされているか、buf が十分に長いかどうかに応じて決定される。
[]バイトから文字列
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf ! = nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
// Assign the underlying pointer
stringStructOf(&str).str = p
// Assign length
stringStructOf(&str).len = len(b)
// Copy data
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b))))
return
}
まず、長さが0か1の場合を処理し、bufを使うか、mallocgcで新しいメモリセクションを要求するかを決定するが、いずれにせよ、データは最後にコピーされる。
ここでは、変換後の文字列のlen属性が設定されています。
の効率的な実装
プログラムが基礎となるデータに変更を加えないことを保証する場合、型の変換のみを行い、データをコピーしないことでパフォーマンスを向上させることができますか?
unsafe.Pointer、int、uintptの3つの型は、同じ量のメモリを消費します。
var v1 unsafe.Pointer
var v2 int
var v3 uintptr
fmt.Println(unsafe.Sizeof(v1)) // 8
fmt.Println(unsafe.Sizeof(v2)) // 8
fmt.Println(unsafe.Sizeof(v3)) // 8
つまり、基本的な構造として、文字列は[2]uintptr、[]バイトスライス型は[3]uintptrと見なすことができるわけです。
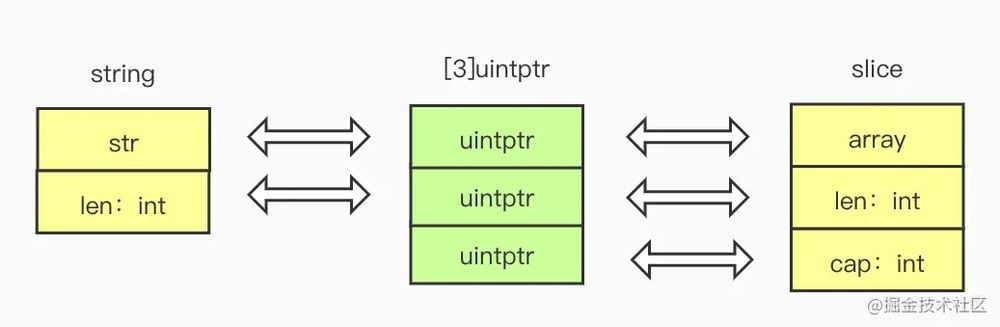
そして、文字列から[]byteへ[3]uintptr{ptr,len,len}をビルドアウトするだけです。
ここで、スライス構造体のcapフィールドを生成していますが、実はここでcapフィールドを生成しなくても読み込み動作に影響はないのですが、以下の理由で変換後のスライスに要素を追加したい場合に問題が発生する可能性があります。
この場合、スライスの cap 属性はランダムで、len よりも大きな値になる可能性があります。この場合、追記時に要素のために新しいメモリセクションを開くのではなく、元の配列の後に追記し、その後ろのメモリが書き込み可能でない場合はパニックになります。
[ポインタの型を変換し、capフィールドを無視するだけです。
実装は以下の通りです。
func stringTobyteSlice(s string) []byte {
tmp1 := (*[2]uintptr)(unsafe.Pointer(&s))
tmp2 := [3]uintptr{tmp1[0], tmp1[1], tmp1[1]}
return *(*[]byte)(unsafe.Pointer(&tmp2))
}
func byteSliceToString(bytes []byte) string {
return *(*string)(unsafe.Pointer(&bytes))
}
ポインターは、異なるタイプのポインターを変換するために使用され、基礎となるデータのコピーは不要です。
性能テスト
次の性能テストは、効率的な実装のためのもので、長さ100の文字列またはバイト配列を変換に使用します。
以下の4つの方法をそれぞれテストしてください。
func stringTobyteSlice(s string) []byte {
tmp1 := (*[2]uintptr)(unsafe.Pointer(&s))
tmp2 := [3]uintptr{tmp1[0], tmp1[1], tmp1[1]}
return *(*[]byte)(unsafe.Pointer(&tmp2))
}
func stringTobyteSliceOld(s string) []byte {
return []byte(s)
}
func byteSliceToString(bytes []byte) string {
return *(*string)(unsafe.Pointer(&bytes))
}
func byteSliceToStringOld(bytes []byte) string {
return string(bytes)
}
テスト結果は以下の通りです。
ベンチマークStringToByteSliceOld-12 28637332 42.0 ns/op
BenchmarkStringToByteSlice-New-12 1000000000 0.496 ns/op
ベンチマークByteSliceToStringOld-12 32595271 36.0 ns/op
ベンチマークByteSliceToStringNew-12 1000000000 0.256 ns/op
性能差が比較的大きく、変換する文字列やバイト配列が長い場合は、さらに性能向上が顕著になることがわかります
まとめ
この記事では、文字列と配列の基本的なデータ構造と、それらをインターリーブする効率的な方法について説明します。ただし、この記事は、プログラムが基本データを変更しないことを保証できるシナリオに適用されるという点に注意してください。もしこれが保証されず、例外が発生するような方法で基礎となるデータが変更される可能性がある場合、コピーメソッドを使用する必要があります。
Goの文字列と[]byteの効率的な相互変換に関する記事は以上です。Goの文字列と[]byteの相互変換については、スクリプトハウスの過去記事を検索するか、以下の関連記事を引き続きご覧ください。
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン