[解決済み] Linux上で動作するC++コードのプロファイリングを行うにはどうすればよいですか?
質問内容
Linuxで動作するC++のアプリケーションを持っていて、最適化を行っている最中です。どのようにしたら、私のコードのどの部分が遅く動作しているのか特定できますか?
解決方法は?
プロファイラを使用することが目的であれば、推奨されるプロファイラのいずれかを使用してください。
しかし、もしあなたが急いでいて、プログラムが主観的に遅くなっている間にデバッガーの下で手動で中断できるのであれば、性能の問題を見つける簡単な方法があります。
何度か停止させて、その都度コールスタックを見ればいいんです。20%とか50%とか、何パーセントかの時間を浪費しているコードがあれば、各サンプルでそれを現行で捕らえることができる確率が高くなります。つまり、それが目に見えるサンプルの割合となるわけです。推測は必要ありません。もし問題が何であるか推測しているのであれば、これはそれを証明または反証するものです。
大小さまざまなパフォーマンスの問題が複数存在する場合があります。そのうちの1つを取り除くと、残りの問題がより大きな割合を占めるようになり、その後のパスで発見しやすくなります。これは 拡大効果 それが複数の問題で複合的に作用すると、実に大きなスピードアップにつながるのです。
注意事項 : プログラマーは、自分で使ったことがない限り、このテクニックに懐疑的な傾向があります。プロファイラがこの情報を与えてくれるというが、それはコールスタック全体をサンプリングし、そのサンプルのランダムなセットを調べさせた場合のみ真実である。(コールグラフは、同じ情報を与えてはくれない。
- 命令レベルではまとめられないし
- 再帰性がある場合、混乱した要約になる。
また、おもちゃのプログラムにしか使えないと言いますが、実際にはどんなプログラムにも使えますし、大きなプログラムではより多くの問題が見つかる傾向があるので、よりうまく機能するようです。問題ではないものを見つけることもあると言いますが、それはあなたが何かを見たときにだけ言えることです。 一度 . 複数のサンプルで問題が見られたら、それは本物です。
P.S. また、Javaのように、ある時点のスレッドプールのコールスタックサンプルを収集する方法があれば、マルチスレッドプログラムでも可能である。
P.P.S 大まかな一般論として、ソフトウェアの抽象化の層が多ければ多いほど、それがパフォーマンス問題の原因(とスピードアップの機会)であることがわかります。
追加 : あまり知られていないかもしれませんが、スタックサンプリングの手法は再帰がある場合にも同様に機能します。その理由は、ある命令を削除することで節約できる時間は、その命令がサンプル内で何回発生するかに関係なく、その命令を含むサンプルの割合で近似されるからです。
もう一つ、よく耳にする反論があります。 ランダムなところで止まってしまうので、本当の問題を見逃してしまいます。 ということです。 これは、本当の問題が何であるかについて、あらかじめ概念を持っていることに起因しています。 性能問題の重要な特性は、予想を裏切ることです。 サンプリングによって何かが問題であることを告げられると、最初の反応は不信感です。 しかし、サンプリングが問題を発見した場合、それが現実であることを確信できます。
追加
: ベイズ的な説明をしてみます。 ある命令があったとします。
I
(呼び出しであろうとなかろうと)その呼び出しスタックにあるいくつかの分数
f
の時間(したがって、その分のコスト)。簡単のために、私たちは
f
が、0.1, 0.2, 0.3, ...のいずれかであると仮定します。0.9, 1.0 のいずれかであり、これらの可能性の事前確率はそれぞれ 0.1 であるため、これらのコストはすべて事前確率が等しいと考えられます。
次に、スタックのサンプルを2つだけ取って、命令を見るとします。
I
を指定すると、両方のサンプルで、観測
o=2/2
. これにより、周波数の新しい推定値が得られます
f
の
I
は、これによると
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
最後の欄には、例えば、以下のような確率があると書かれています。
f
>= 0.5とすると、事前の想定60%から92%になる。
仮に事前の想定が違っていたとします。仮に
P(f=0.1)
は0.991(ほぼ確実)で、それ以外の可能性はほとんどありえない(0.001)。言い換えれば、事前の確実性は
I
は安い。すると、こうなる。
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
これで、次のようになります。
P(f >= 0.5)
は26%で、事前の想定である0.6%から上昇しました。そこでベイズでは、確率的コストの推定値を更新することができます。
I
. データ量が少なければ、コストがどれくらいなのか正確にはわからないが、修正する価値があるほど大きいということだけはわかる。
さらにもう一つの見方として、以下のようなものがあります。
継承のルール
.
コインを2回ひっくり返して、2回とも表が出たとしたら、コインの確率的な重さはどうなるのでしょうか?
答えは、ベータ分布で、平均値が
(number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75%
.
(重要なのは、私たちが
I
回以上です。一度しか見ていなければ
f
> 0.)
つまり、非常に少ないサンプル数でも、目にした命令のコストについて多くのことを知ることができるのです。(そして、平均してそのコストに比例した頻度で目にすることになります。もし
n
のサンプルを取得し
f
がコストだとすると
I
に表示されます。
nf+/-sqrt(nf(1-f))
のサンプルです。例
n=10
,
f=0.3
ということです。
3+/-1.4
のサンプルです)。
追加
: 測定とランダムスタックサンプリングの違いを直感的に感じられるように。
今は壁時計時間でもスタックをサンプリングするプロファイラがありますが
出てくるもの
は測定値(またはホットパス、またはホットスポット、そこからボトルネックが簡単に隠れる)です。表示されないのは、実際のサンプルそのものです(表示されるのは簡単ですが)。そして、もしあなたの目標が
見つける
がボトルネックになっている場合、その数を確認する必要があります。
平均して
, 2 をかかる時間の割合で割ったものです。
つまり、30%の時間がかかるとすると、2/.3 = 6.7 サンプルが平均してそれを示し、20サンプルがそれを示す確率は99.2%です。
ここで、測定値を調べることと、スタックサンプルを調べることの違いを、即興で説明します。 ボトルネックはこのような大きな塊であっても、小さな塊が多数あっても、違いはありません。
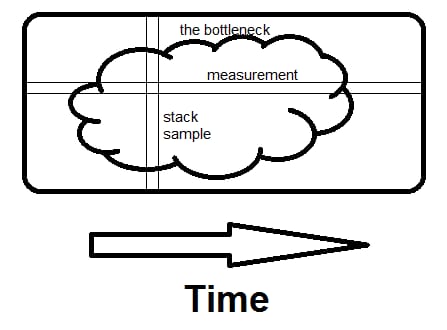
計測は水平方向で、特定のルーチンが何分かかっているかがわかります。 サンプリングは垂直方向です。 その瞬間にプログラム全体が何をしているのか、回避する方法があれば。 で、2回目のサンプルで確認すると ボトルネックを発見したことになります。 それが違いを生むのです。単にどれだけ時間がかかっているかではなく、その理由の全体が見えるのです。
関連
-
[解決済み】C++でint型に無限大を設定する
-
[解決済み】Visual Studio 2015で「非標準の構文。'&'を使用してメンバーへのポインターを作成します」エラー
-
[解決済み] 配列のベクトルを扱う正しい方法
-
[解決済み] Linuxで特定のテキストを含むすべてのファイルを検索するにはどうすればよいですか?
-
[解決済み] 文字列の単語を反復処理するにはどうすればよいですか?
-
[解決済み] static_cast, dynamic_cast, const_cast, reinterpret_cast はいつ使うべきですか?
-
[解決済み] フォルダとそのサブフォルダ/ファイルのパーミッションを一括で変更する方法
-
[解決済み] Pythonスクリプトのプロファイリングはどのように行うのですか?
-
[解決済み] Linux で grep を使ってファイル名だけを表示するにはどうしたらいいですか?
-
[解決済み] Linuxで特定のポートで動作しているプロセスを停止させる方法は?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】getline()が何らかの入力の後に使用されると動作しない 【重複あり
-
[解決済み] [Solved] Error C1083: Cannot open include file: 'stdafx.h'
-
[解決済み】浮動小数点例外エラーが発生する: 8
-
[解決済み】リンカーエラーです。"リンカ入力ファイルはリンクが行われていないため未使用"、そのファイル内の関数への未定義参照
-
[解決済み】VC++の致命的なエラーLNK1168:書き込みのためにfilename.exeを開くことができません。
-
[解決済み】デバッグアサーションに失敗しました
-
[解決済み] 最後の手段としてのパフォーマンス最適化戦略【終了しました
-
[解決済み] DateTime.Nowは関数のパフォーマンスを測定するのに最適な方法ですか?[クローズド]
-
[解決済み】いくつかの良い.NETプロファイラーとは何ですか?
-
[解決済み] gprofの代替品 [終了しました]。