linuxでの正規表現grepのちょっとしたまとめ
正規表現
は、特定の文字列にマッチする文字列の集合の特徴を記述するために使用されるパターンです。パターン記述は、特殊文字+通常の文字で行われ、テキストマッチング目的のツールを実現する。一般的な人物の検索と同様に、特徴を記述することで "一致する人物を検索する"
現在では、レギュラーが広く使われるようになり、様々なテキストエディタ/テキスト処理ツールに組み込まれるようになった
アプリケーションシナリオ** バリデーション。**フォーム送信時のユーザー名とパスワードの検証。**検索。**大量の情報の中から、指定された内容を素早く抽出する。一括で指定したURLの検索 置き換える。 指定された形式のテキストを取り出し、通常検索でマッチングさせ、特定のものに置き換える、(vimのテキスト置換など)
多くの技術分野(自然言語処理、データストレージなど)では、正規表現を使えば簡単に欲しい情報を抽出できるので、この部分は基本的な要素を形成するのに必須である 文字クラス 番号修飾子 位置の修飾子 特殊記号
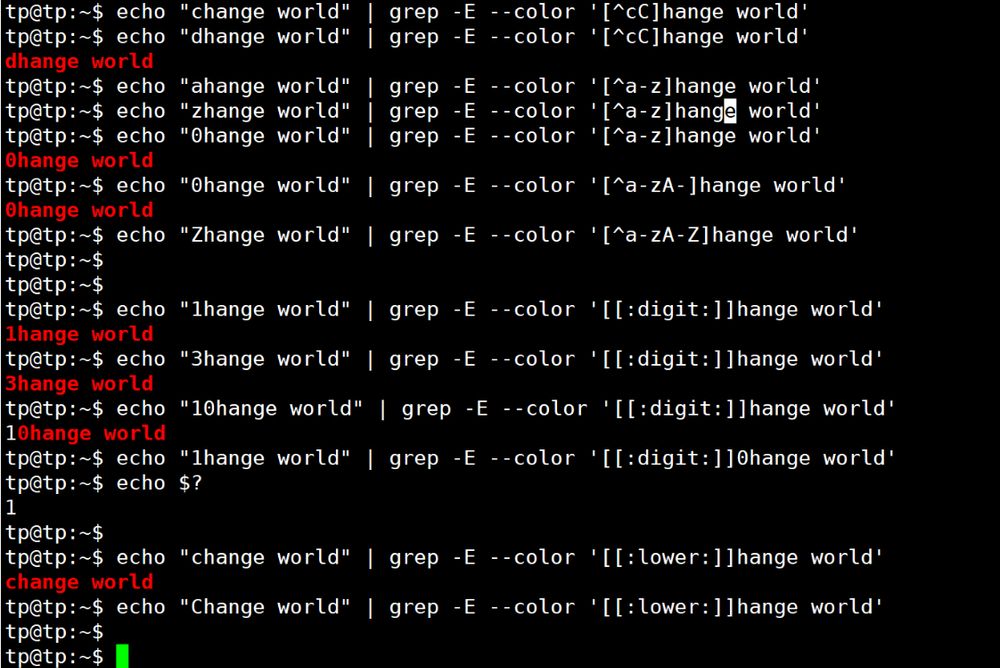
1. キャラクターのクラス。
{テーブル キャラクター 説明 使用例 本文 . のいずれかにマッチします。 A 文字 abc . abcd, abc0 などにマッチング可能。 [] のいずれかの文字にマッチします。 [012]aは0a、1a、2aにマッチします。 括弧内の文字範囲 例えば、[0-9]は任意の数字にマッチします。 ^ の前に[]を付けると、括弧内以外の文字にマッチします。 [^ab]c は 1c, dc にマッチしますが、ac, bc にはマッチしません。 {を使用します。 [[:xxx:]] grepツールであらかじめ定義されたいくつかの名前付き文字クラス [[:digit:]] は数字に、[[:alpha:]] は文字に、[[:lower:]] は任意の小文字にマッチするなど、様々なマッチングが可能です。アプリケーション
grep は --color オプションを使って、マッチする文字列を赤でマークします。 Linuxでは、echo $? を使うと、最後にコマンドを実行したときの終了コードが表示されます。0が実行成功、1が失敗を示します。 {が表示されます.
以下のように実験してください。

注意事項 使用方法 . のデフォルトは greedy matching で、これは後述する正規のマッチング方法と関係がある。
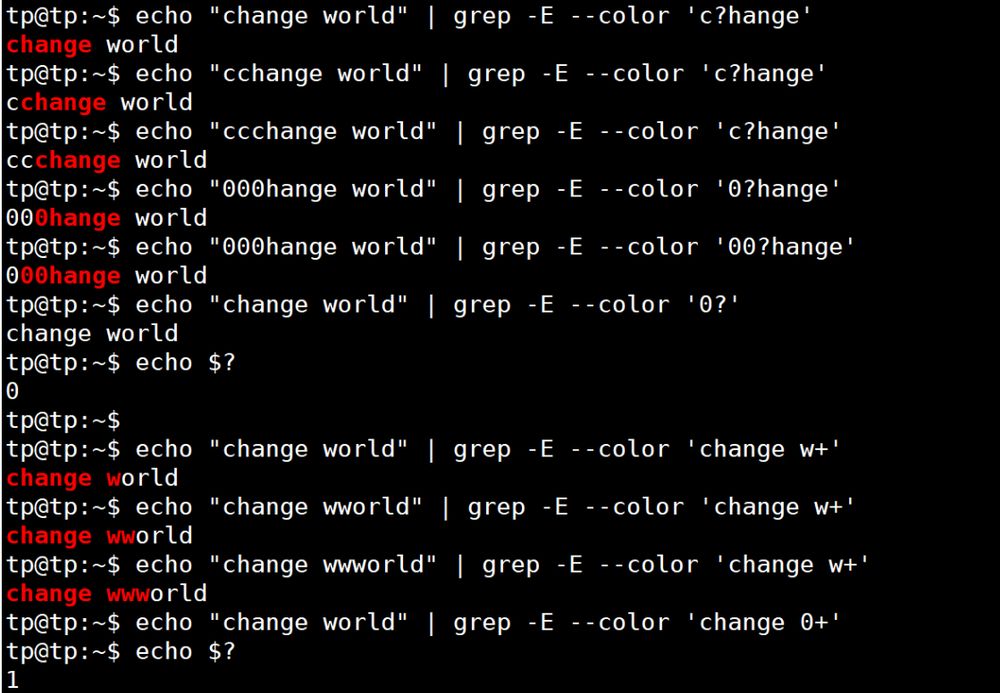
2. 数量修飾語。
{テーブル キャラクター 説明 使用例 本文 ? 直前のセル(直前の数字または文字)に0回または1回マッチする 小数点以下の数字にマッチする場合は 0\...? [0-9] は 0.1 , 0.2, 0.3, などにマッチします。 . {を使用します。 は正規のコードでは特殊な記号なので \ をエスケープするために使用します(詳細は後述します)。 + 直前のセルに1回以上一致すること [a-zA-Z0-9_. -]+@[a-zA-Z0-9_. -]+.com 電子メールアドレスに一致する * 直前のユニットと0回以上一致すること [0-9][0-9] *少なくとも1桁の数字にマッチします。 {N} 直前のセルとN回完全に一致する [0-9]{3}は000から999までの数字にマッチします。 {N,} 直前のセルに少なくともN回一致すること [0-9]{3,}は3桁以上の数字にマッチします。 {,M} 直前のセルに最大M回までマッチする [0-9]{,1}は以下と同じです。 [0-9]? {N,M} {を使用します。 直前のセルにN~M回マッチする おおよその一致するIPアドレス [0-9]{1,3}\. [0-9]{1,3}\. [0-9]{1,3}\. [0-9]{1,3}アプリケーション
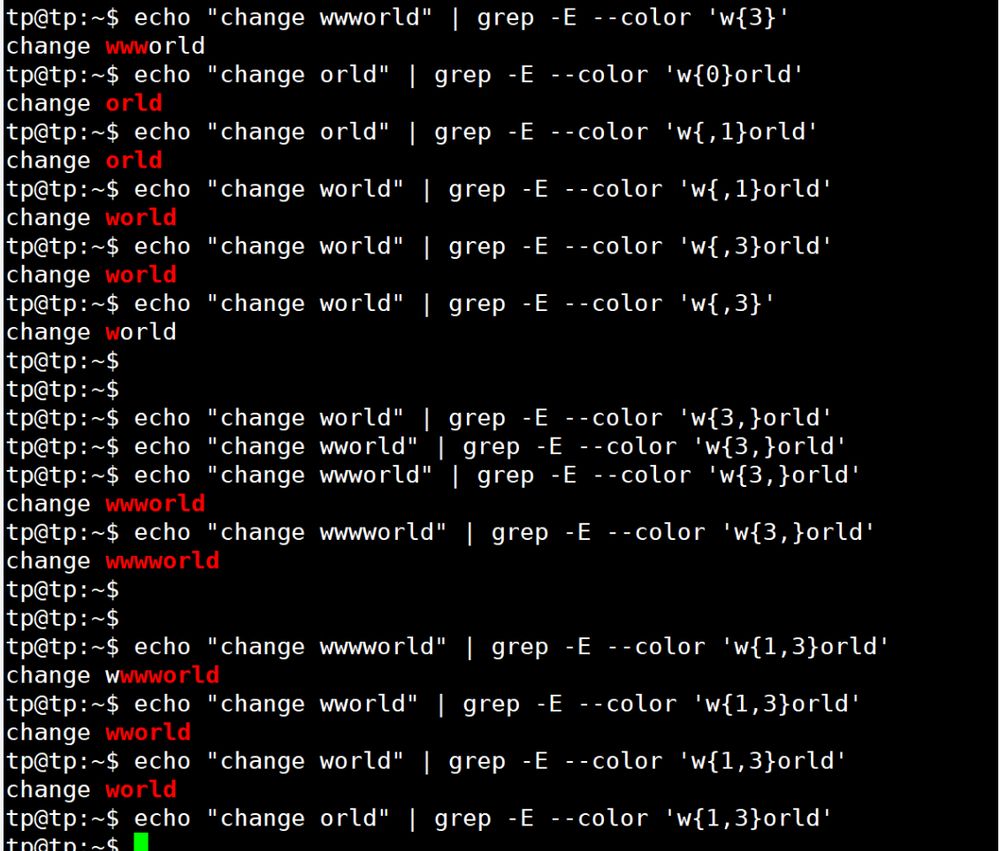
3. ポジションの修飾語
{テーブル キャラクター 説明 使用例 本文 ^ 行頭の位置を、行頭から順に一致させる ^world 行頭のworldにのみマッチします。 $ 行末から始まる行末位置のマッチング ;$ 行末の;記号に合わせると ^$ 空行にマッチする < {を使用します。 マッチ 単一単語の開始 位置 < thマッチ this, doesn't match teach, ethernet \> 一致 語末 位置 {を使用します。 matches sleep, leap, etc, does not match parent, sleepy {を使用します。 \b 単語の開始位置、終了位置を一致させる {を使用します。 例えば \ʕ-̫͡-ʔ は世界、aorldにマッチします。 \b ororldのみマッチング \B {を使用します。 非単語の先頭と末尾の位置を一致させる {を使用します。 例えば、attend, hatなどのatで始まる単語ではなく、batteryにマッチします。 .注意事項
ここで、Ⓐは対象文字列の中に指定した文字列で始まる単語があるかどうかを認定するためのもので、これを単語境界と呼んでいます。\b は非単語境界と呼びます。
アプリケーション

4. 特別なシンボル
{テーブル キャラクター 説明 例 本文 \ エスケープ文字、普通の文字が特殊文字にエスケープされる、特殊文字が普通の文字にエスケープされる < は単語の頭に合わせるために < と表記し、.の前に \ をつけると、.と表記します。 \. 取る . のリテラル値は () 正規表現の一部を単位に囲むには、単位全体を表す数値修飾子を使用します ([0-9]{1,3}...) {3}[0-9]{3} は、IP アドレスにマッチします。 |strong 2つの部分式を結合して、orの関係を表します。 {を使用します。 n(o|either)はnoまたはeitherにマッチします。 {を使用します。アプリケーション
( )は全体として包含を囲み、その後に番号修飾を行う。

|{{strong
は、どれか1つでもマッチする限りマッチする複数の条件をカスケード接続するために使用されます。
パーサー
を使用することができます。

その他の一般的な文字セットの正規表現版とその置換形
{テーブル シンボル は次のものと同じです。 マッチ 本文 \d [0-9] 数字 \D [^0-9] 数字以外の文字 \w [a-zA-Z0-9_] のようなものです。 数字文字に下線を引く \W [^\w] 数字以外のアルファベットのアンダースコア \s (フランス語) 表や改行などの空白部分 \S [^\s] 空白でない部分では、これらの記号を使えば、正規表現を簡単に書くことができるのですね。試してみましょう。

しかし、結果は私たちが望むものではないようですね?実はこれ、正規表現バージョンと関係があるんです。 正規表現にはいくつかのバージョンがあります。
基本正規表現、別名ベーシックRegEx、別名BREs 拡張正規表現、別名拡張RegEx (ERE) Perl正規表現(PREの場合はPerl RegExとも呼ばれる)。
grepのデフォルトは基本ルール、-Eオプションは拡張ルール、-PパラメータはPerlバージョンのルールです。前の問題を解決するために、-Pオプション付きのgrepはここで解決することができます。
正規表現の拡張仕様と基本仕様のバージョンの違いは、基本的に同じです。ただし、Basicでは、一部の文字 ? +{}|() は通常の文字として解釈し、上記の特殊な意味を持つ文字については、「escape」を用いてエスケープする必要があります。逆に、Extended仕様では、? +{}|() は特殊な意味と解釈され、そのリテラル値を取って \-translated する必要があります。つまり、grepツールで-Eオプションを付けると、マッチングに拡張正規を使うということです(あるいは、単に イーグレップ コマンドを使用)、なければ基本ルールが使用される。Pオプションは パールレギュラーマッチ . これはperl言語に統合された最も重要な機能の一つで、多くの言語が正規サポートを設計する際に基本的にPerlの正規表現を参照するほど強力な機能です。正規表現のマッチングパターン
貪欲モード
grepコマンドは、できるだけ多くのマッチングを行うために、デフォルトで greedy matching を使用します。
この場合、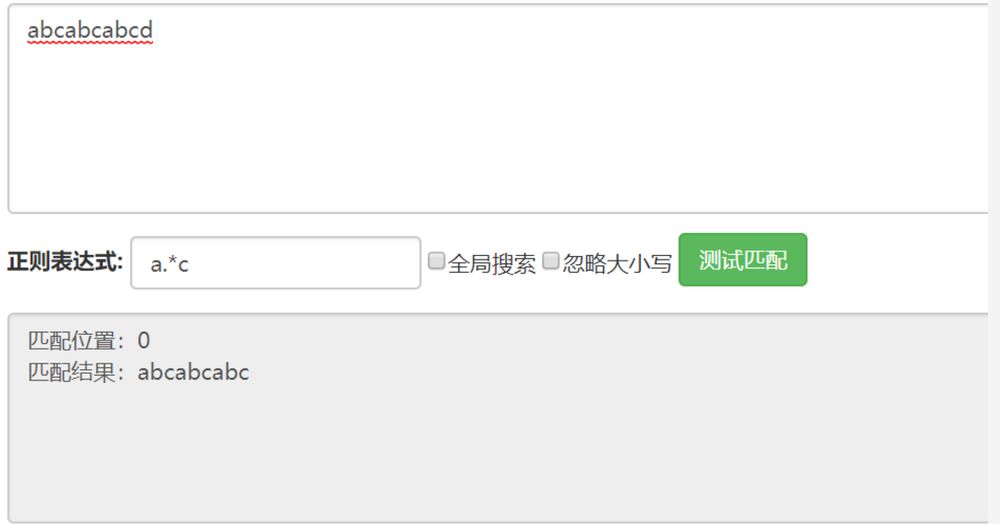 ノングリーディモード
ノングリーディモード
正規表現がマッチするとき、できるだけ少ない数のマッチになります。つまり、一度マッチするとすぐにマッチしてしまい、 (次のマッチのセットを開く g オプションがない限り) 続かないということです。

要約すると ご覧の通り、非貪欲モード識別子である、貪欲モード識別子の後に?
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン