MySQL Innodb インデックスメカニズム詳細解説
1. インデックスとは
インデックスとは、ストレージエンジンがレコードを素早く見つけるために使用するデータ構造である。
2. インデックスに利用できるデータ構造について
- シーケンシャルルックアップ構造。このルックアップは非常に非効率的であり、複雑度はO(n)である。大容量データに対するクエリーの効率は非常に低い。
- データを順序よく並べる。二分探索法は、折半探索法とも呼ばれる。
一度の比較で検索間隔を半分に狭める。また、MySQL のデータは順序付き配列ではありません。
- 二分木: 左側のサブツリーのキー値は常にルートのキー値より小さく、右側のサブツリーのキー値は常にルートのキー値より大きい。中次の探索で得られる配列は順序付き配列であるが、二項探索木の構成が悪いと、順序付き探索と変わらなくなる
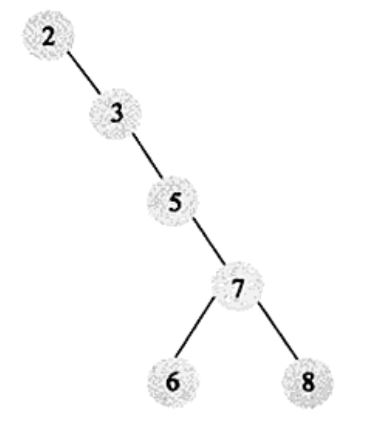
- バランスの取れたバイナリツリー。二分木が釣り合う必要がある場合、これは釣り合い二分木につながる。平衡二分木は、まず二分木の定義を満たし、次に任意のノードの2つの部分木の高さの最大差が1であることを満たさなければならない。明らかに上の木は平衡二分木ではなく、平衡二分木の例は以下の通りである。
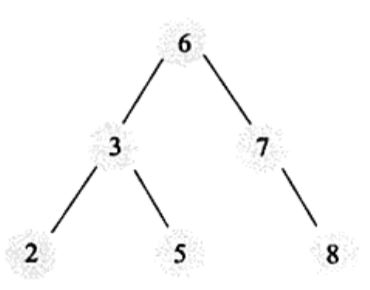
バランスドバイナリルックアップツリーの時間複雑度はO(logN)で、確かに問い合わせは高速だが、バランスドバイナリツリーを維持するのも非常にコストがかかる。一般に、挿入や更新の後にバランスを取るには、1回以上の左右のスピンが必要です。
- B-ツリー。B-treeは平衡2分木と少し異なり、多項木、別名平衡多方向ルックアップツリーである。
- ルートノードが少なくとも2つの子を持つ(各ノードはM-1個のキーを持ち、昇順に並べられる) 他のノードが少なくともM/2個の子を持つ
- リーフノードはすべて同じレベルである。
- B+ツリー
B+木は、B木と索引順次アクセス法(実際の場面ではほとんど使われない)から発展したB木の変種である。
B+木は、ディスクやその他のダイレクトストレージの補助として設計されたバランスド・ルックアップ・ツリーである。
B+木のすべてのレコードノードは、キー値の大きさの順に同じレベルのリーフノードに配置され、各リーフノードへのポインタによって接続されている。
すべてのクエリーはリーフノードを参照し、クエリーパフォーマンスは安定しています。
すべてのリーフノードが順序付きチェーンテーブルを形成しているため、クエリーの範囲指定が容易である。各リーフノードは隣接するリーフノードへのポインターを保持し、リーフノード自体はキーワードサイズによって小さいものから大きいものへと順次リンクされている(双方向チェーンテーブル)。
3. InnodbがB+木をインデックスとして使用する理由
- システムのディスクへのブロック読み出し機能を有効に利用し、同一ディスクブロックを読み出しながらできるだけ多くのインデックスデータをロードすることで、インデックスのヒット効率を高め、その結果ディスクIOリードの回数を減らすことができます(局所性原理とディスク先読み)。
- B+木はディスクの読み書きのコストが低い:B+木の内部ノードはキーワード固有の情報へのポインタを持っていない(リーフノードのみ格納)ため、その内部ノードはB木に比べて小さく、同じ内部ノードのキーワードがすべて同じディスクブロックに格納されていれば、ディスクブロックが保持できるキーワードが増えるほど、一度にメモリに読み込む必要があり、相対IO 読み書き回数は少なくなります。
- B+木は、クエリ効率の面でより安定しています。なぜなら、非終端ノードは最終的にファイルの内容を指すノードではなく、リーフノードにあるキーワードのインデックスに過ぎないからです。そのため、キーワード検索はすべてルートノードからリーフノードへのパスを取る必要がある。すべてのキーワード検索は同じパス長を持ち、その結果、各データの検索効率は同等になる。
- B+木はレンジクエリをサポートするが、B木はサポートしない
4. インデックス分類
記憶構造による分類。BTreeインデックス、Hashインデックス、フルテキストインデックス
用途別:主キーインデックス、ユニークインデックス、コンバインドインデックス
物理ストレージの観点から:集約インデックスと非集約インデックス(補助インデックス)
ここで、アグリゲーションインデックスとは何か、非アグリゲーションインデックスとは何かについて説明します。
- アグリゲートインデックス
B+木は各テーブルの主キーに従って構築され、リーフノードにはテーブル全体の行記録データが格納される。アグリゲーションインデックスのリーフノードはデータページとも呼ばれ、各データページは双方向の連鎖で結ばれている。
集計インデックスは、主キーのソート検索やデータの範囲検索を非常に高速に行うことができます。
- 補助インデックス
インデックスカラムを格納するだけでなく、リーフノードへのポインタも格納する。
今回は以上ですが、学習の参考になれば幸いです。また、スクリプトハウスを応援していただければ幸いです。
関連
-
MySQLのWhereの使用方法について説明します。
-
MySQLのselect、distinct、limitの使い方
-
MySQLデータ型の詳細
-
MySQLインデックスベースストレステストの実装
-
SpringBootのMySQLへの接続は、バックエンドのインターフェイスの操作方法を書き込むためのデータを取得するために
-
面接では選択式で聞かれましたが......。.for updateはテーブルをロックするか、行をロックするか?
-
mysqlインデックスが長すぎる特殊なキーが長すぎる解決策
-
[解決済み] ユニークなテーブル/エイリアスではない
-
Mysql がエラーを報告 オペランドには 1 つのカラムが含まれている必要があります。
-
SQLステートメントエラーです。オペランドには 1 つのカラムを含める必要があります [括弧を追加せずに複数のフィールドをクエリする
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
MySQLデータベース・インデックスの左端一致の原則
-
MySQLにおけるorder byの使用方法の詳細
-
MySQLデータベースでvarchar型の数値の大きさを比較する方法
-
MySQLはこのようなUpdateステートメントを書くべきではありません
-
MySQLインストールチュートリアル(Windows用)詳細
-
MysqlからElasticsearchにデータを同期させる方法を説明します。
-
[解決済み] [GROUP BY句に含まれるか、集約関数で使用される必要があります。
-
[解決済み】マルチパート識別子をバインドできない
-
Djangoマイグレーションエラー 外部キー制約を追加できない
-
mysql がエラーを報告します。不明な文字セットです。'utf8mb4'