行列の平均と標準偏差を詳細に計算するPython Numpyの実装
I. 前書き
CRITIC重み付け法は、エントロピー法や標準偏差法よりも優れた客観的重み付け法である。
- 指標間の対比の強さと指標間の対立の評価に基づいて、指標の客観的な重みを測定するものです。指標のばらつきの大きさを考慮しながら指標間の相関を考慮し、数字が大きければ大きいほど重要というわけではなく、データそのものの客観的性質を利用して科学的な評価を行うものです。
- コントラスト強度とは、同じ指標について、様々な評価スキーム間でとられる値の差の大きさを指し、標準偏差の形で表される。標準偏差が大きいほど変動が大きい、つまり、シナリオ間でとられる値の差が大きいほど、重みが増す。
指標間の対立は、相関係数で表される。2つの指標が互いに強い正の相関を持つ場合、矛盾が少ないほど重みが低くなります。
また、2つの指標間の正の相関が大きい場合(相関係数が1に近いほど)、対立は小さくなり、2つの指標はプログラムのメリットを評価する上でより類似した情報を反映していることが示されます。
Python で CRITIC 重み付け法を再現する場合、標準偏差で表される変動係数を以下のように算出する必要がある。
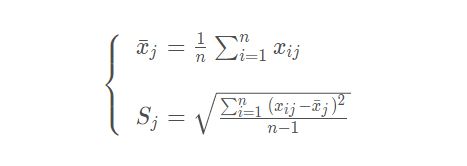
Sjはj番目の指標の標準偏差を示す。CRITICの重み付け手法では、各指標の中で取った値の差の揺らぎを示すために標準偏差を用いており、標準偏差が大きいほど、その指標の値の差が大きいほど、より多くの情報をスクリーニングでき、その指標自体の評価力が強く、より重きを置くべきことを示している。
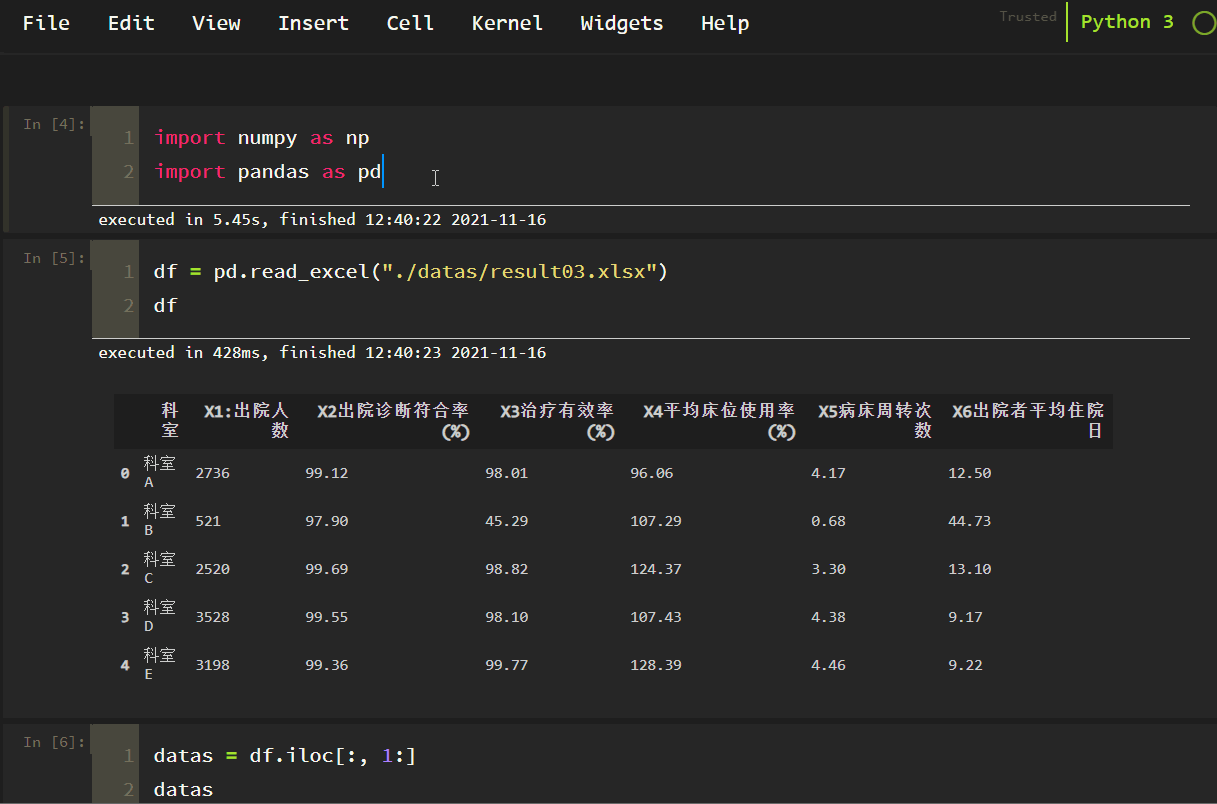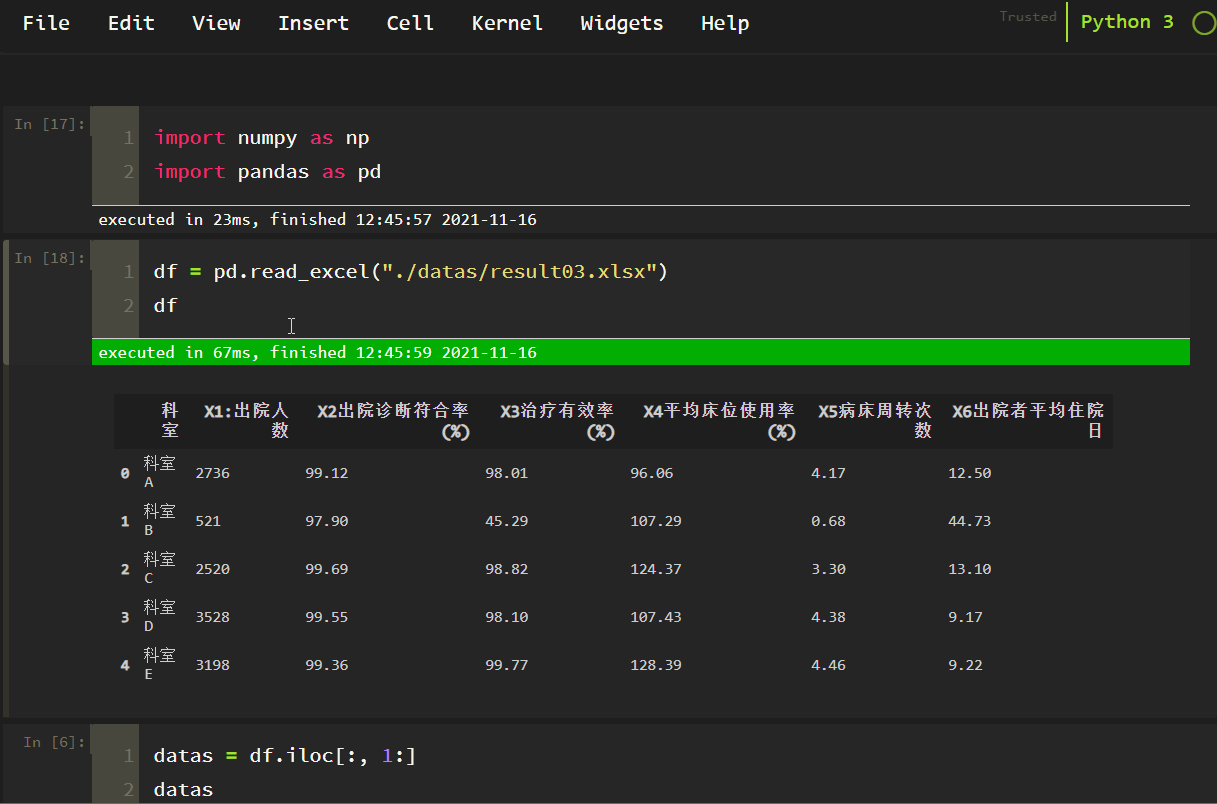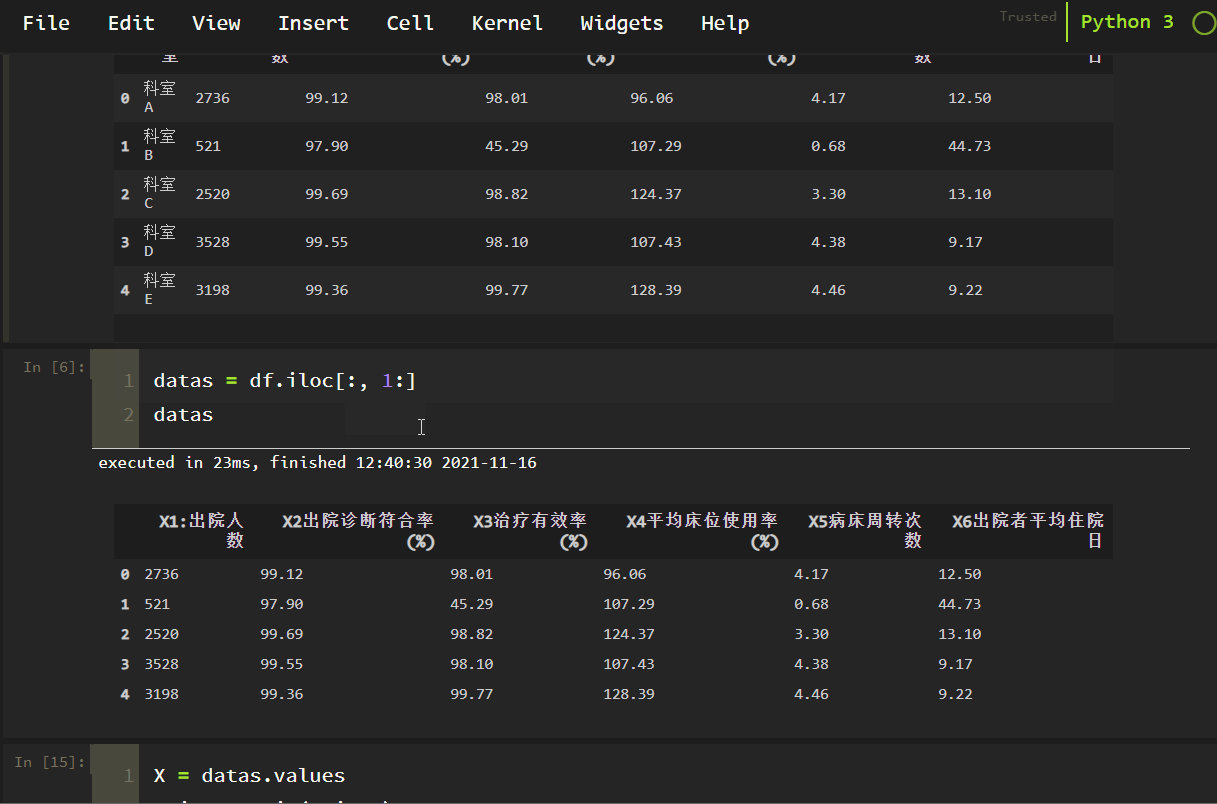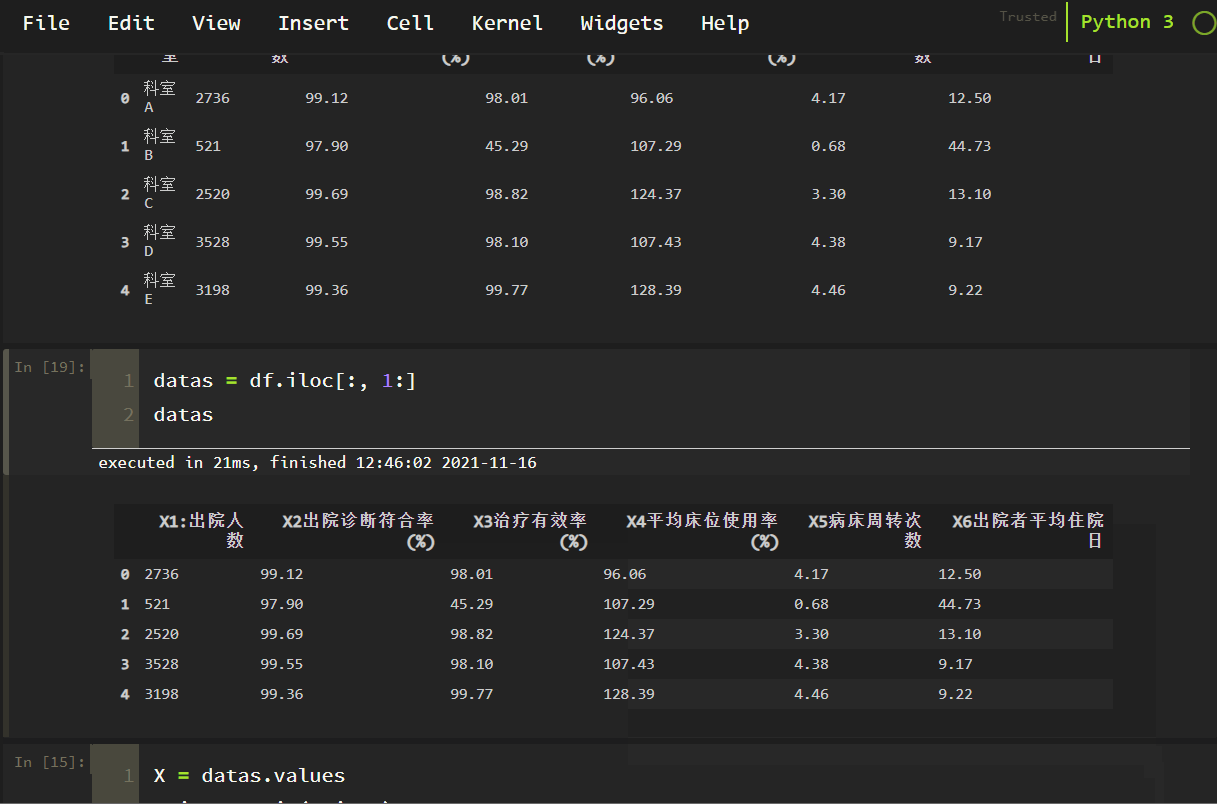
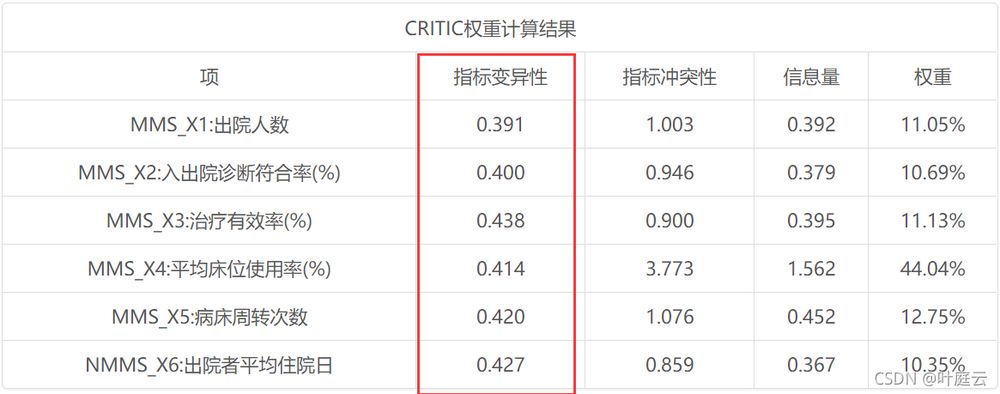
<スパン この研究では、2011年に湖南省のある病院の5つの診療科から6つの指標でデータを収集しました。現在の希望は、入手したデータを通じて、各指標の重み付けがどのようになっているかを分析し、その後の総合評価、各部門の総合比較などのために、病院側が各指標の重み付けを簡単に設定できるようにすることである。データは以下の通りです。
II. 平均と標準偏差の計算の詳細
簡単な行列を初期化します。
a = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9])
])
a
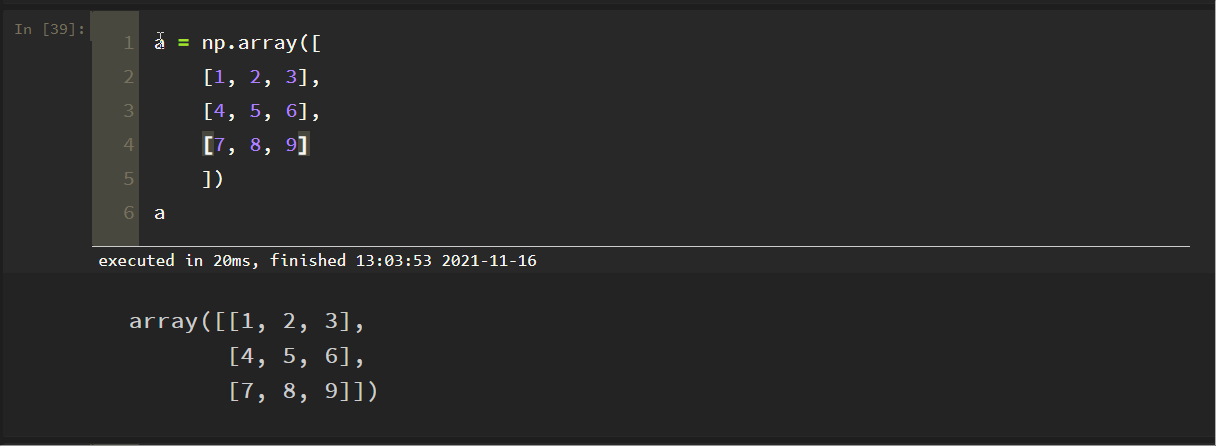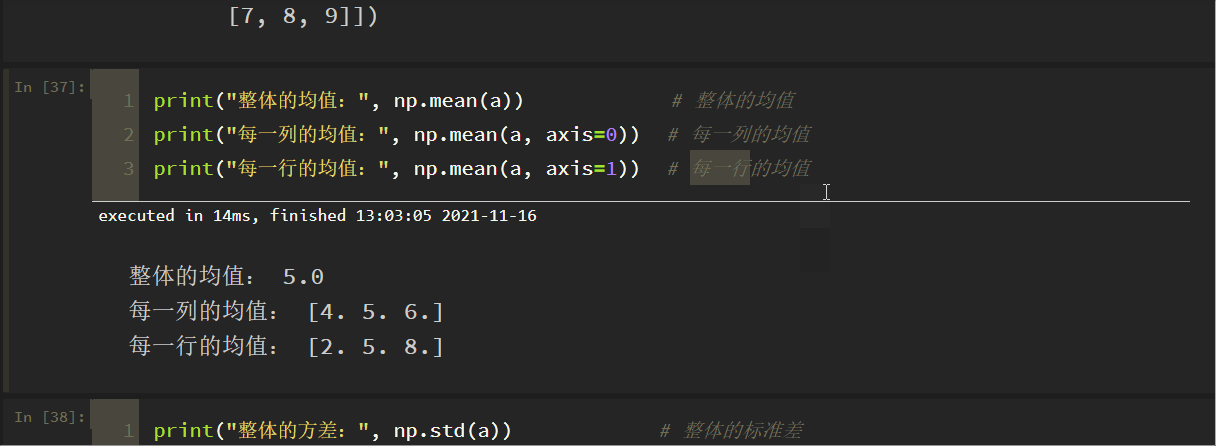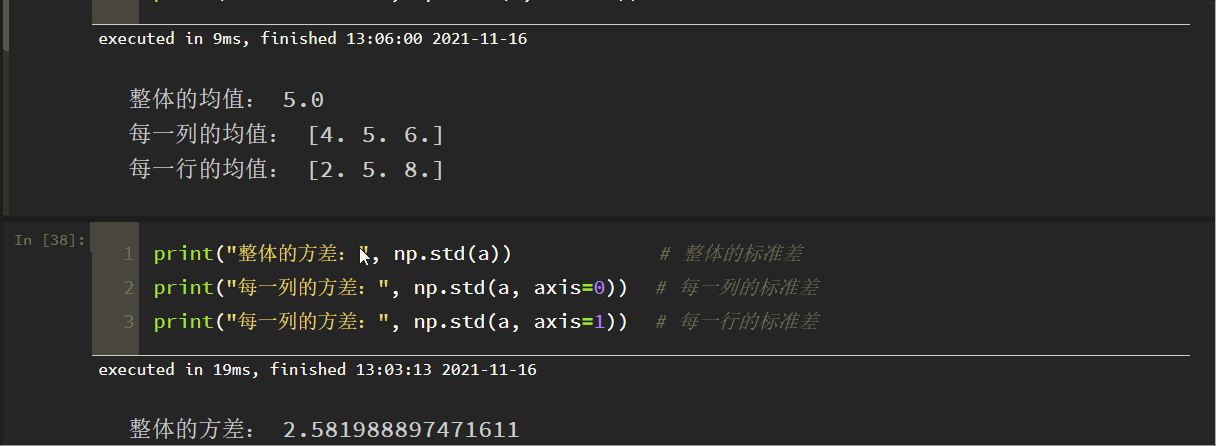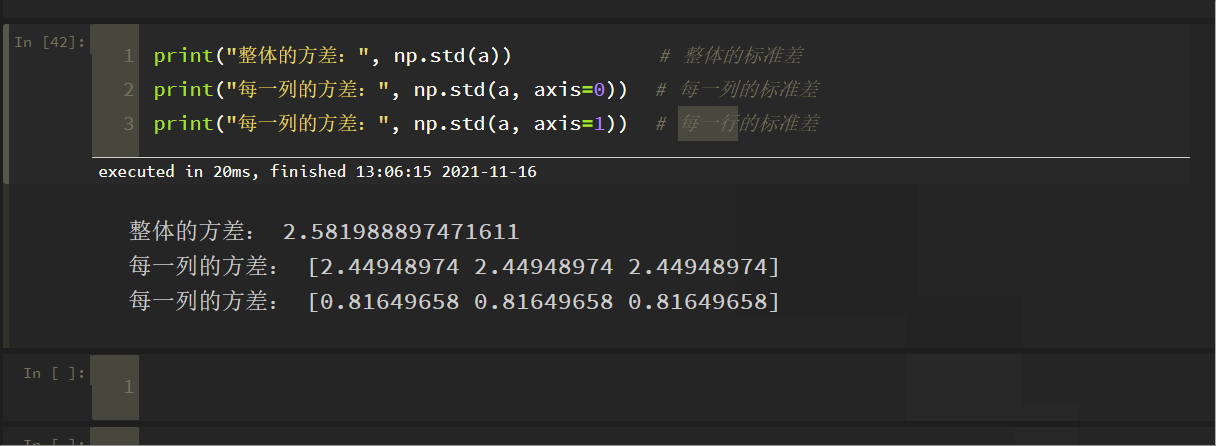
全体の平均、各列の平均、各行の平均を別々に計算します:。
print("Mean of the whole: ", np.mean(a)) # Mean of the whole
print("Mean of each column: ", np.mean(a, axis=0)) # Mean of each column
print("Mean of each row:", np.mean(a, axis=1)) # Mean of each row
全体の標準偏差、各列の標準偏差、各行の標準偏差をそれぞれ計算せよ。
print("Variance of overall: ", np.std(a)) # Standard deviation of overall
print("Variance of each column: ", np.std(a, axis=0)) # Standard deviation of each column
print("Variance of each column:", np.std(a, axis=1)) # Standard deviation of each row
結果は次のようになります。
III. 実践編 CRITIC重み付け法による変動係数の算出
必要な依存ライブラリをインポートする。
import numpy as np
import pandas as pd
データを抽出する。
df = pd.read_excel(". /datas/result03.xlsx")
df
datas = df.iloc[:, 1:]
datas
以下に示すとおりです。
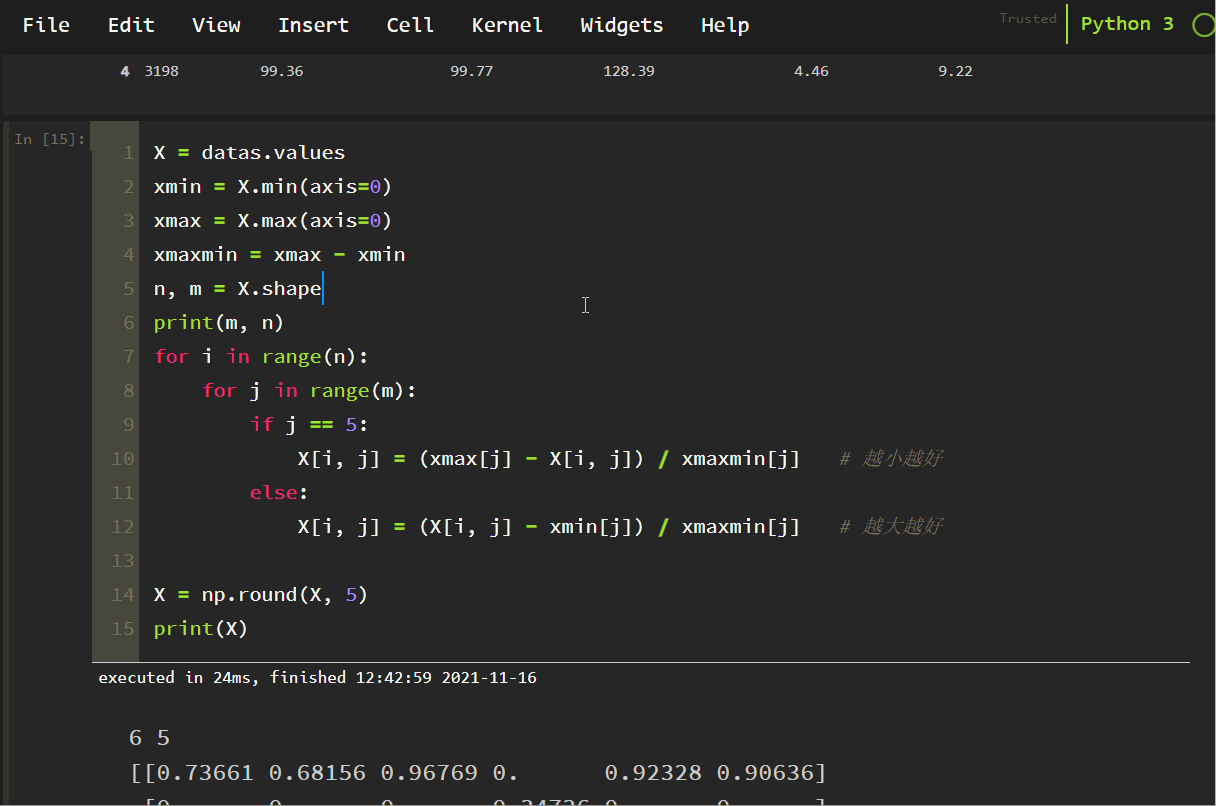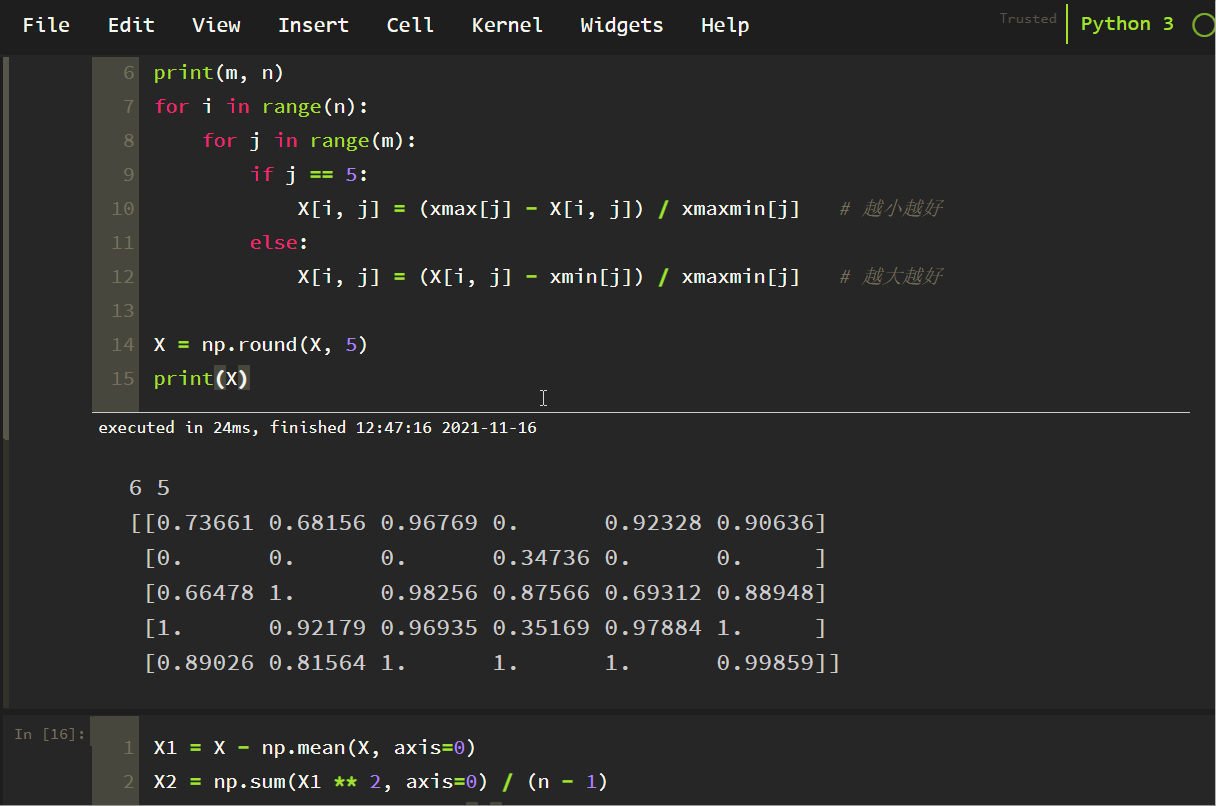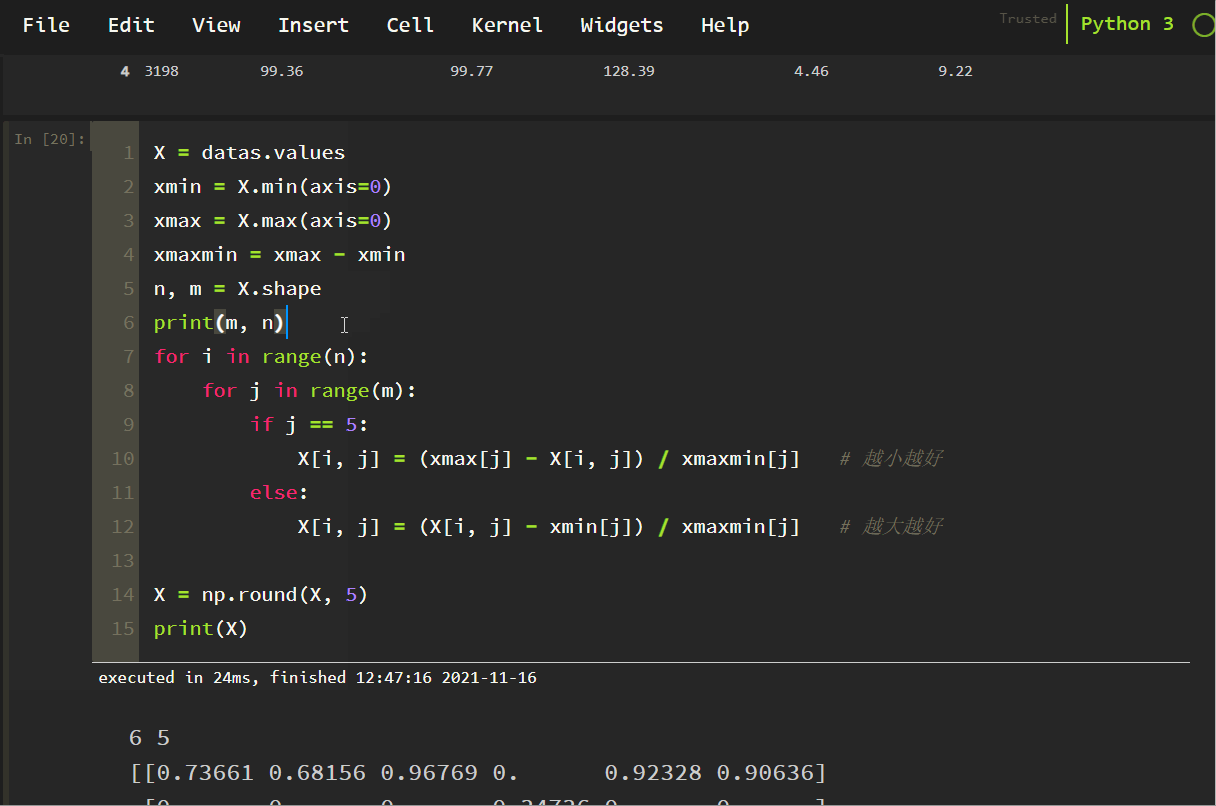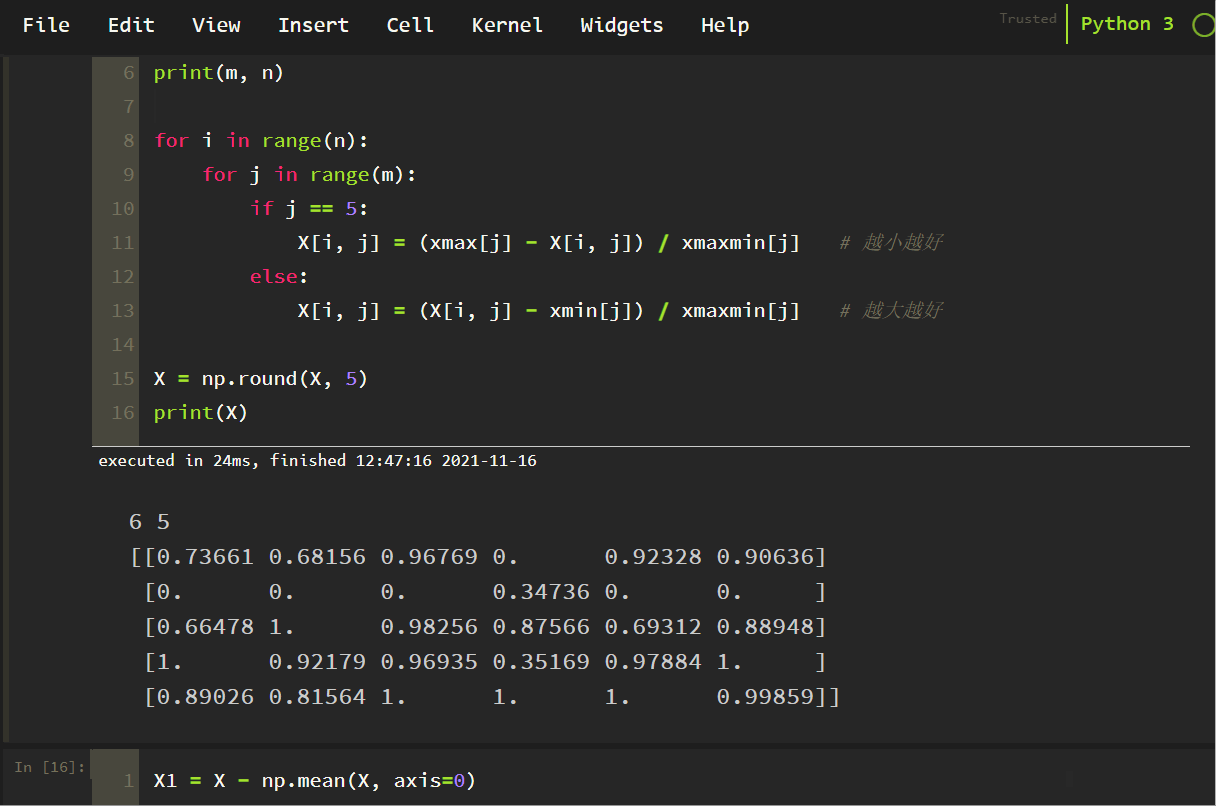
<スパン データの順方向処理と逆方向処理。
X = datas.values
xmin = X.min(axis=0)
xmax = X.max(axis=0)
xmaxmin = xmax - xmin
n, m = X.shape
print(m, n)
for i in range(n):
for j in range(m):
if j == 5:
X[i, j] = (xmax[j] - X[i, j]) / xmaxmin[j] # the smaller the better
else:
X[i, j] = (X[i, j] - xmin[j]) / xmaxmin[j] # the larger the better
X = np.round(X, 5)
print(X)
以下に示すように
各指標のデータの標準偏差を列ごとに示したもの。
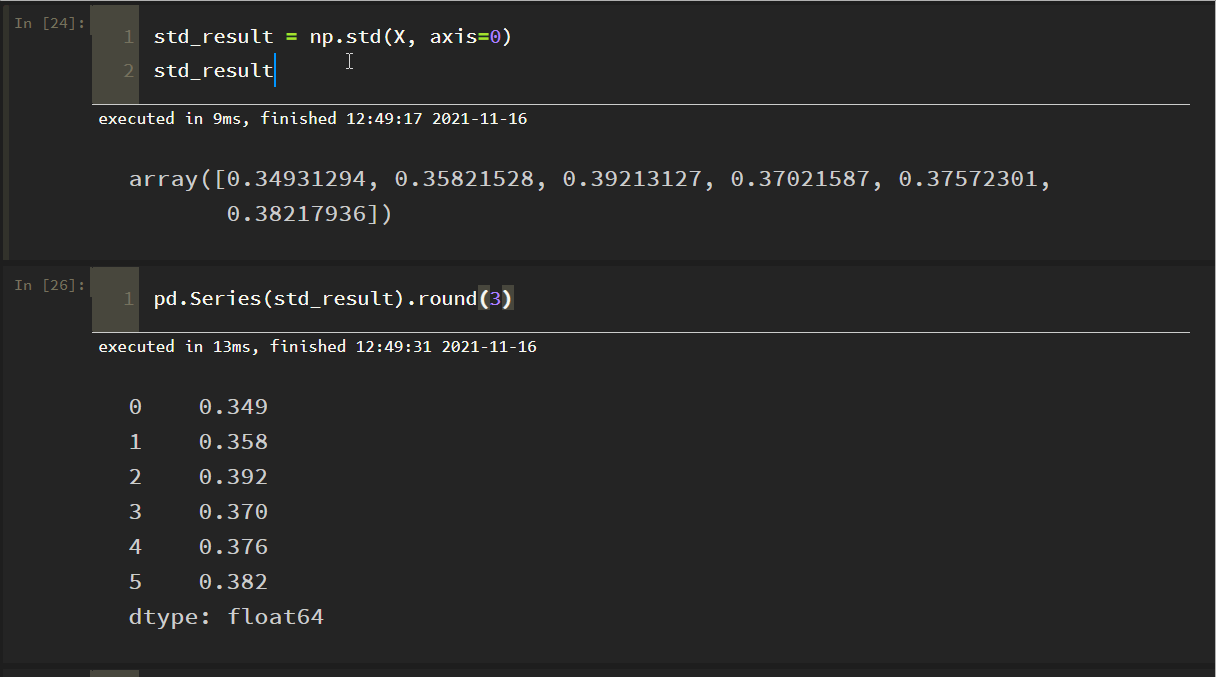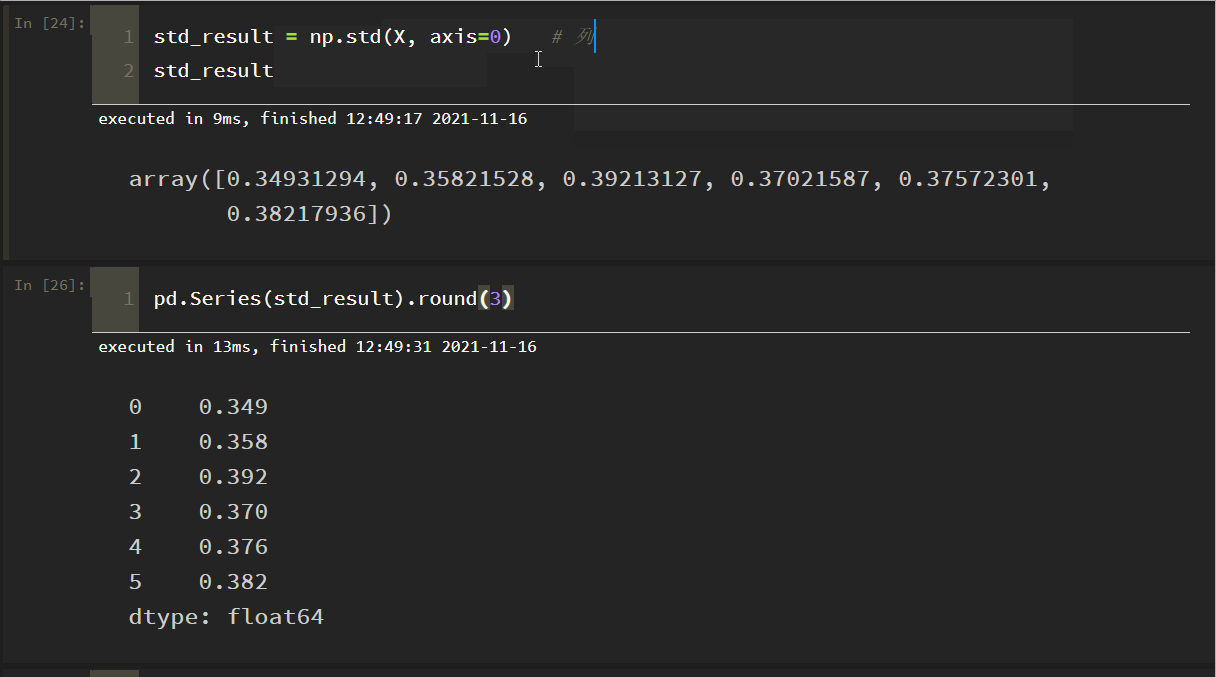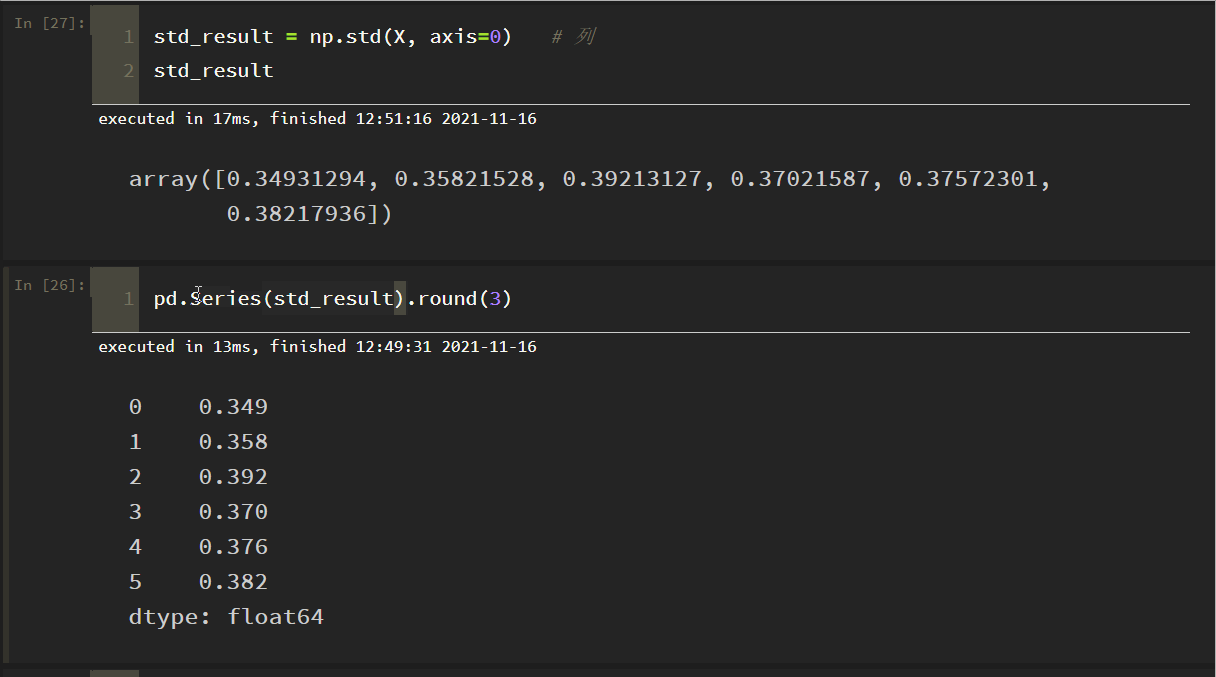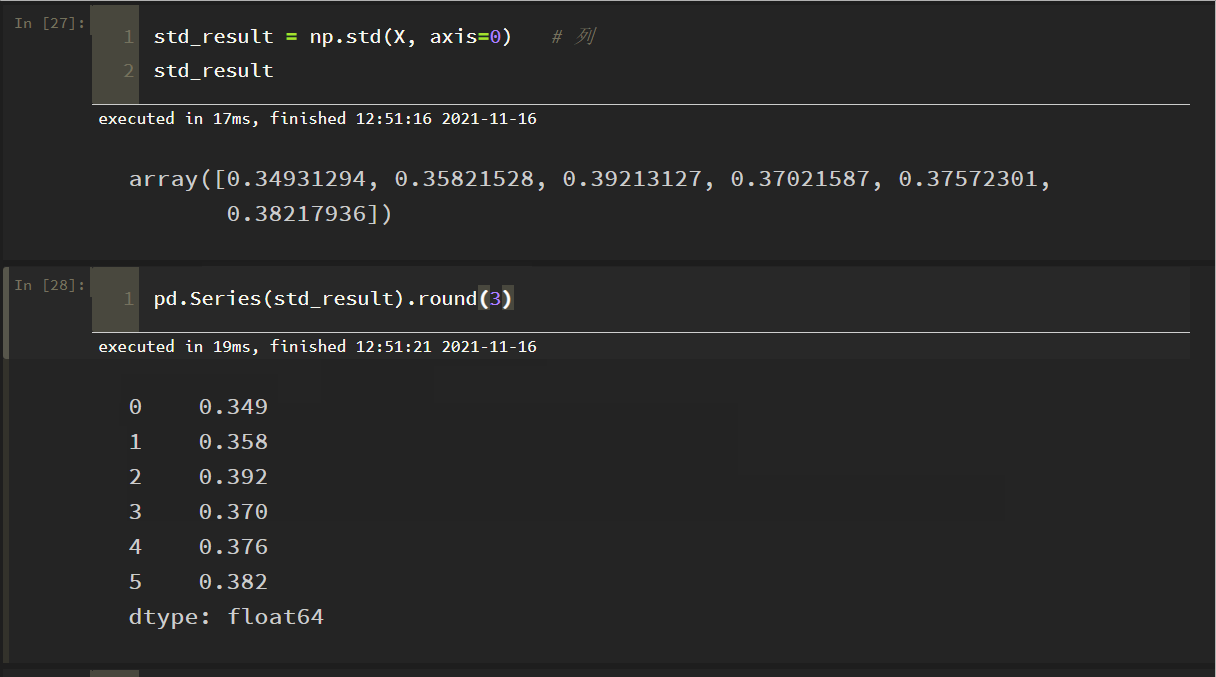
のドキュメントと矛盾していることが判明しました。
理由:numpyのデフォルトは、親標準偏差を得るためにサンプル数で割り、サンプル標準偏差を得るためにサンプル-1で割ることで、パラメータddof=1を設定し、それだけです
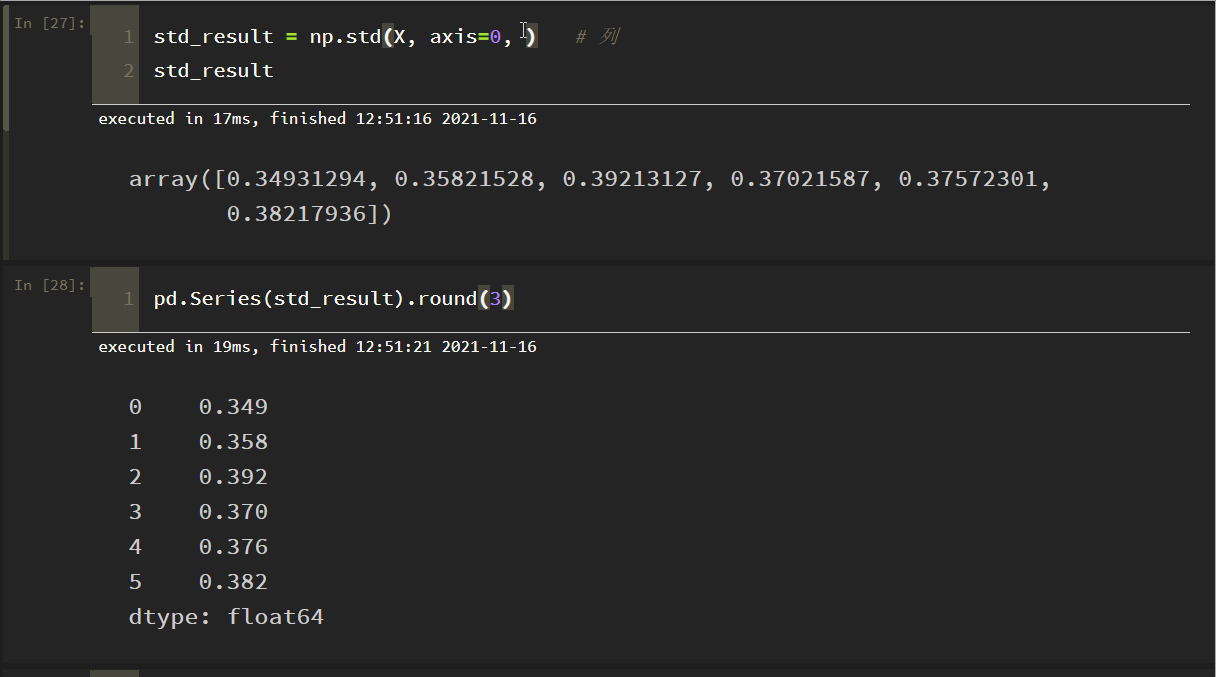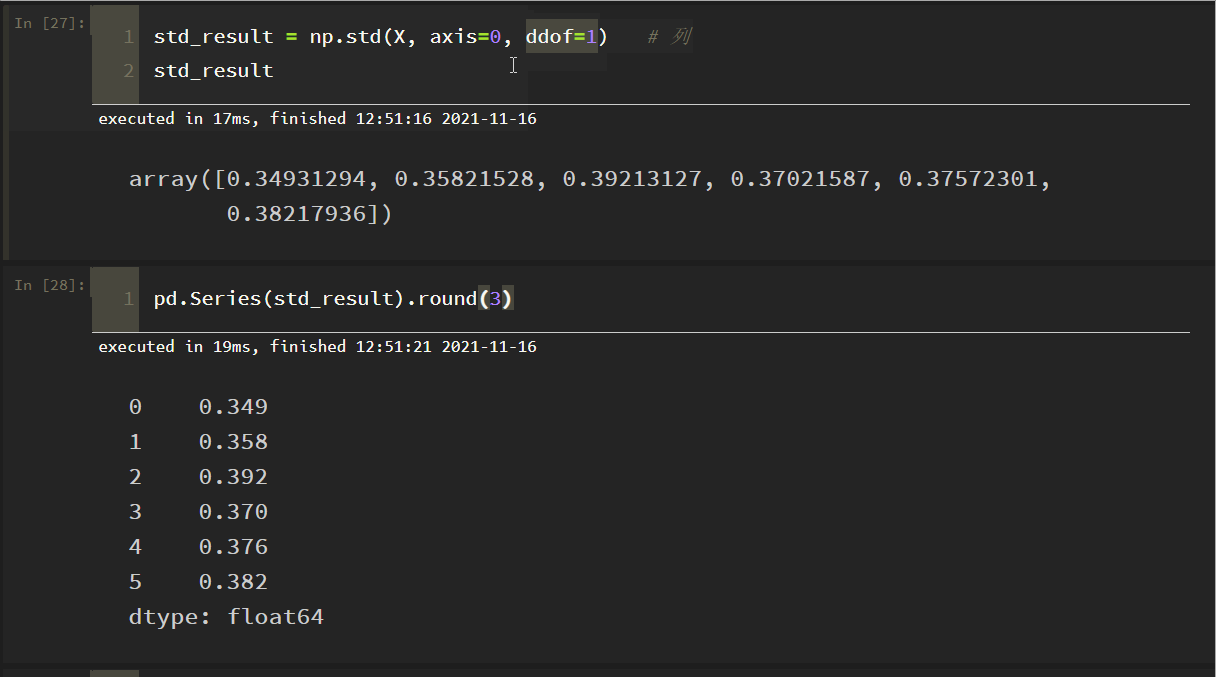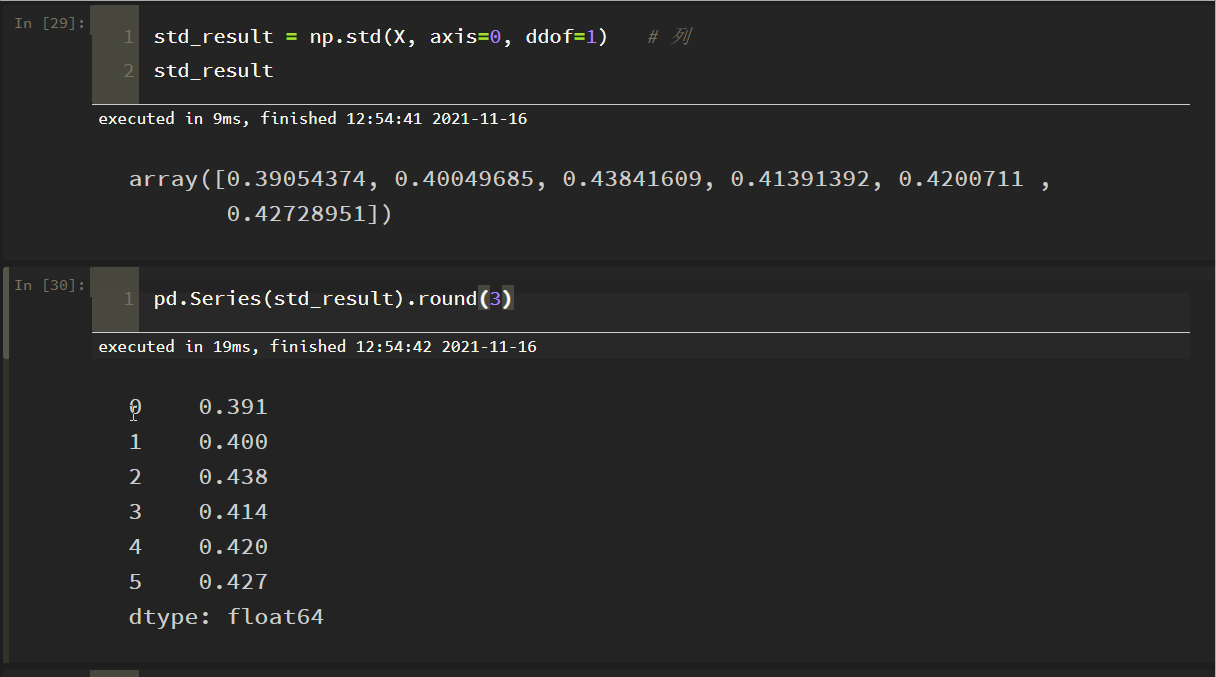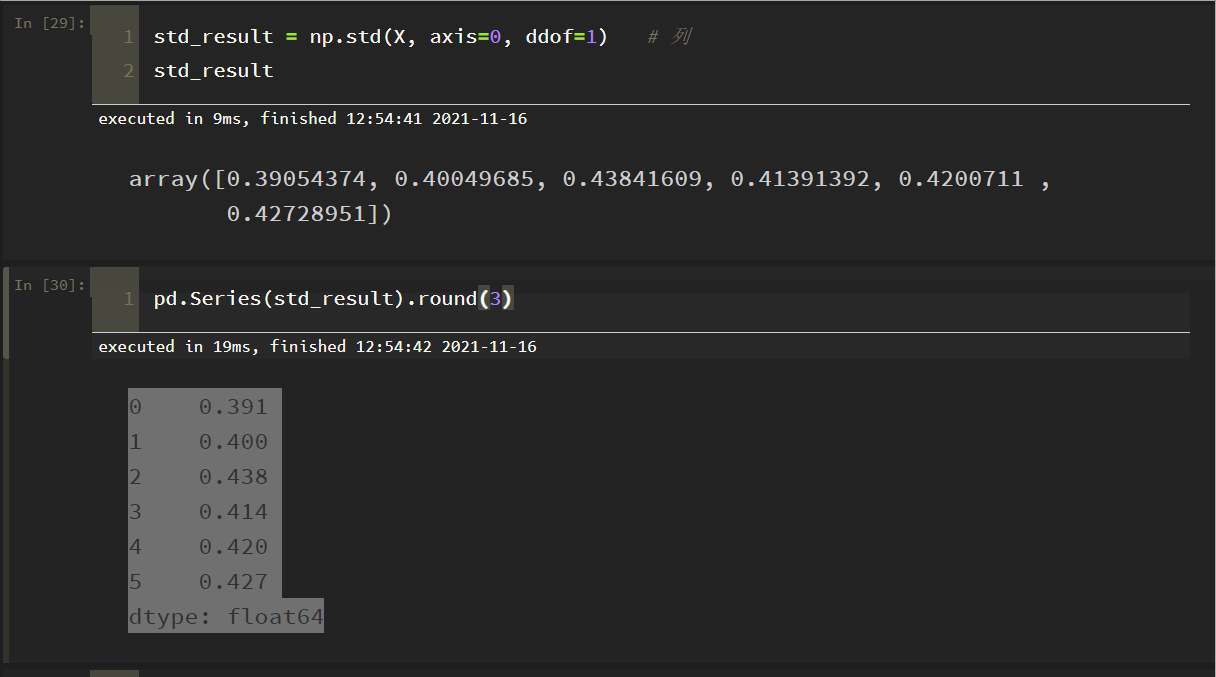
上で見たように、これはドキュメントの結果と一致します!
以上、行列の平均と標準偏差を計算するPython Numpyの実装について詳しく説明しましたが、行列の平均と標準偏差を計算するPythonについての詳細は、Script Houseの他の関連記事にも注目してください
関連
-
[解決済み】LogisticRegression: Pythonでsklearnを使用して、未知のラベルタイプ: '連続'を使用しています。
-
TclError 表示名がない、$DISPLAY 環境変数がない問題が解決されました。
-
[解決済み] データ型「datetime64[ns]」と「<M8[ns]」との違い?
-
[解決済み] Pythonの変数を'undefined'に設定する方法は?
-
[解決済み] Flask SQLAlchemy の Column タイプとオプションの一覧はどこにあるのでしょうか?
-
[解決済み] 引数のアンパッキング:名前付き引数のみが*式の後に続くことができます。
-
[解決済み] ImportError: dateutil.parserという名前のモジュールはありません。
-
[解決済み] JSONデータを文字列として返すAWS Lambda
-
[解決済み] Pythonのサブプロセスpopenの使い方 [重複]。
-
Pythonの各種実行時エラー(SyntaxError : invalid syntaxなど)。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】Python TypeError: 'set' オブジェクトは添え字が使えない
-
[解決済み] django:django.core.exceptions.AppRegistryNotReady: アプリはまだロードされていません
-
[解決済み] オフセットロールフォワードと月オフセット追加後のパンダの境界外ナノ秒のタイムスタンプ
-
[解決済み] numpy配列の0要素を効率的にカウントする?
-
[解決済み] Errno 10060] 接続先が一定時間経過しても適切に応答しないため、接続に失敗しました[closed]。
-
[解決済み] Pyinstaller "サイトモジュールのインポートに失敗しました"
-
[解決済み] TensorFlowチュートリアルのbatch_xs, batch_ys = mnist.train.next_batch(100) のnext_batchはどこから来ているのでしょうか?
-
[解決済み] Matlabのset関数に相当するPythonの関数
-
[解決済み] リクエスト'を解決できません。このモジュールにはインテリセンスがない可能性があります。Visual Studio/Python
-
python TypeError: 'builtin_function_or_method' オブジェクトは反復可能なキーではありません。