Pythonで数行のコードでdablを使ったデータ処理解析とML自動化
データサイエンス・モデルの開発には、データ収集、データ処理、探索的データ分析、モデリング、デプロイメントなど、さまざまな要素が含まれます。機械学習や深層学習のモデルを学習させる前に、データセットをクリーニングし、学習に適した状態にする必要があります。多くの場合、これらのプロセスは繰り返され、多くの時間を占めます。
この問題を克服するために、今日は、データの前処理、特徴の可視化と分析、モデリングなど、機械学習モデル開発を自動化するオープンソースのPythonツールキット「dabl」を紹介します。気軽にブックマークして学習し、「いいね!」して応援してください。
ダブリュー
dablは機械学習のモデリングを簡単にするデータ解析の基本ライブラリで、様々な機能を備えており、数行のPythonコードで加工、分析、モデリングを行うことができます。
インストール方法
pip install dabl
1. データの前処理
dablは、データ前処理パイプラインを数行のPythonコードで自動的に実行します。dablは、欠損値の特定、冗長な特徴の削除、特徴のデータ型の理解などの前処理ステップを実行し、さらに特徴エンジニアリングを実行することができます。
dablが検出した特徴タイプの一覧は以下の通りです。
continuous
categorical
date
Dirty_float
Low_card_int
free_string
Useless
dablは1行のPythonコードで、全てのデータセットの特徴を上記のデータ型に自動的に分類します。
df_clean = dabl.clean(df, verbose=1)
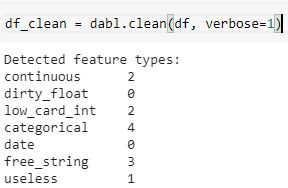
オリジナルのタイタニックデータセットには12個の特徴があり、dablはそれらを上記のデータタイプに自動的に分類し、さらなる特徴エンジニアリングを行います。またdablは、任意の特徴のデータタイプをオンデマンドで変更する機能を提供します。
db_clean = dabl.clean(db, type_hints={"Cabin": "categorical"})
detect_types()関数を使用すると、各フィーチャーに割り当てられたデータ型を確認することができます。
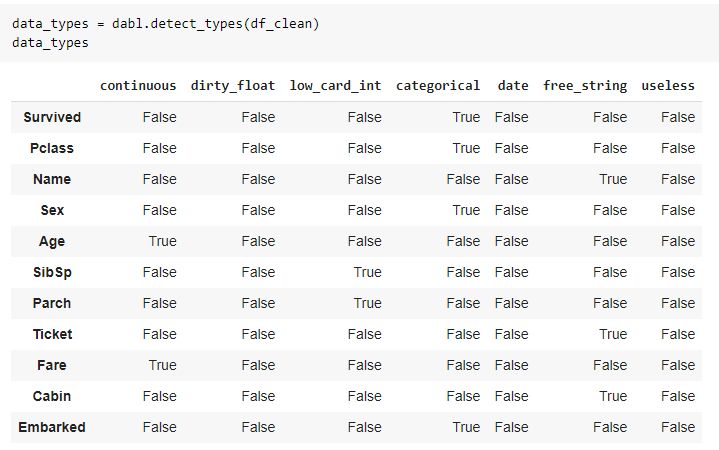
2. 探索的データ解析
EDAは、データサイエンスモデル開発のライフサイクルの重要な部分です。SeabornやMatplotlibなどは、データセットをよりよく理解するために様々な分析を行う可視化ライブラリです。dablはEDAを非常に簡単にし、多くの時間を節約します。
dabl.plot(df_clean, target_col="Survived")
dablのplot()関数は、以下のような様々なプロットを行うことで可視化を実現します。
- ターゲット分布の棒グラフ
- 散在ペアプロット
- 線形判別分析
dablは、データセットに対して自動的にPCAを実行し、データセットの全特徴に対する判別PCAプロットを表示します。
3. モデリング
dablはトレーニングデータ上で様々なベースライン機械学習アル ゴリズムをトレーニングし、モデリングワークフローを加速させ、最 高性能のモデルを返します。dablは簡単な仮定を行い、ベースラインモデ ルのメトリックを生成します。
モデリングは、dablのSimpleClassifier()関数を使って行うことができ、素早く最適なモデルを返します。

まとめ
Dablは機械学習をより簡単かつ高速にする便利なツールで、数行のPythonコードでデータクリーニング、特徴の視覚化、ベースラインモデルの開発を行うことができます。
もっと詳しく知りたい方は、GitHubをご覧になってみてください。 https://github.com/amueller/dabl
上記は、データ処理解析とML自動化の詳細を達成するために、コードの数行をdablを使用するパイソンであり、dablのデータ処理解析とML自動化についての詳細は、スクリプトの家に他の関連記事に注意を払うようにしてください
関連
-
[解決済み】Python regex AttributeError: 'NoneType' オブジェクトに 'group' 属性がない。
-
[解決済み】matplotlibのbbox_to_anchorとloc
-
[解決済み】AttributeError: 'list' オブジェクトに 'lower' 属性がない gensim
-
[解決済み】散布図カラーバー - Matplotlib
-
[解決済み】TypeError: generatecode() は位置引数を0個取るが、1個が与えられた
-
python : true_divide で無効な値に遭遇しました。
-
[解決済み] NameError: name 're' is not defined [duplicate].
-
[解決済み] プログラムの最初にループバックする方法 - Python [duplicate]
-
[解決済み] 空の配列に対するValueErrorを克服する
-
PIPはランチャーでFatal errorが発生します。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】「SyntaxError.Syntax」は何ですか?Missing parentheses in call to 'print'」はPythonでどういう意味ですか?
-
[解決済み】Pytesseract : "TesseractNotFound Error: tesseract is not installed or it's not in your path", how do I fix this?
-
ValueErrorを解決する。同一ラベルのシリーズオブジェクトしか比較できない
-
[解決済み] TypeError: シーケンスアイテム 0: 予想される文字列、int が見つかりました。
-
[解決済み] Pythonでランダムなブール値を取得する?
-
[解決済み] ビューは HttpResponse オブジェクトを返しませんでした。代わりに None を返しました。
-
[解決済み] Pythonの[]と[[]]の違いについて
-
[解決済み] Selenium web-driverのユーザーエージェントを変更する。
-
numpy实用技巧(一)
-
python3 学習メモ 1 - TypeError: 'dict' オブジェクトが呼び出し可能でない 解決法