[解決済み] Ruby で PDF 文書を解析する
2022-02-19 11:09:49
質問
あるフォルダに、ある構造を持つ複数のPDF文書があります。
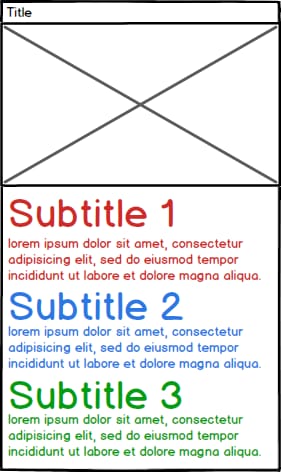
今度は、PDFから情報を解析できるようにしたいと思います。段落の長さがバラバラなことに注意してください。
もちろん、問題を解決してくれとは言いませんが、どうすれば実現できるのか、いくつかのポイントが必要です。
以前nokogiriを使用したことがあり、技術的にはそのようなものが必要ですが、PDFのためです。
つまり、私の例の擬似的な結果は、次のようになります。
- ItemA
- Title: ItemA
- File: 123456789.pdf
- Image: ImageA.png (the image was stored on disk)
- Subtitle1: Content for subtitle 1
- Subtitle2: Content for subtitle 2
- Subtitle3: Content for subtitle 3
- TitleB
- [...]
解決方法は?
pdf-reader
は解決策の一つです。しかし、それは時々それが適切な形式でテキストを与えることができない問題があります。私はそれを使用しています。
を使用することをお勧めします。 ドックスプリット . pdf-reader」と「docsplit」については、以下のページで詳しく説明しています。 このブログの記事 .
お役に立てれば幸いです。何か説明が必要な場合は、遠慮なくコメントください。
関連
-
[解決済み] Rubyがブロックの中でパイプ文字を使うことについて、誰か説明してください。
-
[解決済み] Rubyでファイルを移動するにはどうしたらいいですか?
-
[解決済み] Rubyで指定されたディレクトリが存在するかどうかを確認する方法
-
[解決済み] 文字列をfloatやintにパースするにはどうしたらいいですか?
-
[解決済み] Bashでコマンドライン引数を解析するには?
-
[解決済み] PHPでHTML/XMLをパースして処理する方法とは?
-
[解決済み] Rubyのswitch文の書き方
-
[解決済み] PDFファイルの適切なMIMEメディアタイプ
-
[解決済み] HTMLにPDFを埋め込むおすすめの方法とは?
-
[解決済み】なぜPythonはこのJSONデータをパースできないのですか?[終了] PythonがこのJSONデータをパースできないのはなぜですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] Rubyのローカル変数が未定義である
-
[解決済み] Rubyのメソッド'to_sym'は何をするのですか?
-
[解決済み] Rubyのコロン演算子とは何ですか?
-
[解決済み] Rubyでランダムな文字列を生成する方法
-
[解決済み] Rubyでリモートホストの到達可能性をpingで確認する方法
-
[解決済み] Rubyで日付文字列をパースする
-
[解決済み] ファイルの存在を確認する方法 [重複]について
-
[解決済み] Ruby で配列の順序を逆転させる
-
[解決済み] プロキシ(ISA-NTLM)の後ろからRuby Gemsをアップデートする方法
-
ERRORの問題を解決します。rails のインストール時に gem ネイティブ拡張のビルドに失敗しました。