SQL実行エンジンを自作する方法
前書き
データベースに関する情報をいろいろと読んでいるうちに、データベースの車輪を作ることを思いつかずにはいられなくなりました。データベースの基本原理をしっかりと理解したことを確認するためです。データベースFreedomと名付け、githubにアップしました。
全体構造
車輪を作るのですから、当然、フロントエンドのネットワーク・プロトコルのやり取りからバックエンドのファイル・ストレージまで、すべてをジャックしなければなりません。ここにFreedomの実装のための一般的なモジュールを含む全体的な構造があります。

最終的なストレージ構造は、もちろん古典的なB+ツリー構造です。B+ツリーとファイルシステムのブロックとの変換は、もちろんBuffer(Page)Managerを通して行われる。もちろん、トランザクションを完了させるためには、ログマネージャを通して動作するWALプロトコルも使用する必要があります。
Freedom はテーブルを整理するためにインデックスを使用し、DruidSQL Parse は sql を対応するインデックス演算子に、したがって対応する意味的な操作に変換します。
MySQL プロトコル構造
クライアント/サーバー間のやり取りはMySQLプロトコルを使用し、mysqlクライアントとjdbcとのやり取りを容易にする。
クエリパケット
mysqlは3バイトの固定長パケットヘッダでパケットを分割することで、tcpストリームリードの問題を解決しています。そして、アプリケーションレベルでパケットが連続しているかどうかを判断するために、sequenceIdが使用されます。

結果セットパケット
mysql プロトコルの最も複雑な部分は、その結果セットの読み取りであり、NIO の方法で複雑さを増しています。
Freedomは、Nettyフレームワークにおいて、一連の読み取り状態を設定することで、この問題をよりよく解決しています。

列パケット
もっと簡単なのは、上記のように行のフォーマットを読み込んで、それを段階的に解析していくだけです。

プロトコルのパース部分は比較的簡単なので、ここでは説明しません。
SQLパース
Freedomはパーサーとして定評のあるDruid SQL Parseを使用しています。実際、SQLのパースとは、SQLの内容を表現することです。
実際、sqlの解析はsqlのセマンティクスを一連の演算子としてテキストで表現する方法です(スペースの都合上、ここではselectでフィルタリングする場所の根拠を述べるにとどめます)。
whereの処理
whereの後の述語は、例えば以下のように、ツリー構造で整理された一連のSQL式として表現することができる。

アクセス層がカーソルを介して一連の行を提供すると、ツリー式を使ってwhereの要件を満たすデータをフィルタリングすることができます。druidはParseの共通ビジターを使って、上記の式の計算操作を簡単に処理することができます。
結合の取り扱い
結合に関する最も単純な解決策は、以下のように、2つのテーブルのデカルト積を行い、上記のwhere条件でフィルタリングすることです。

フリーダムの還元型デカルト積の扱いについて
FreedomはB+木を基礎の記憶構造としているので、B+木のスキャン(検索)の範囲(つまり、B+木種の中で最大検索キーと最小検索キーがどこにあるか)はwhere述語で定義することが可能です。次のようなSQLを考えてみましょう。
select a.*,b.* from t_archer as a join t_rider as b where a.id>=3 and a.id<=11 and b.id>=19 and b.id<=31
そして、以下のように、インデックスidにおけるaのスキャン範囲は[3,11]と定義される。

bのスキャン範囲は、以下のように[19,31]である(プロットを容易にするため、両方の表に同じデータを仮定している)。

スキャンが15*15(合計15要素)サイクルから4*4サイクルに減少、すなわちサイクル数が7.1%に減少
もちろん、結合条件がある場合、Freedomは基礎となるカーソル再帰の間にデータの一部を事前にフィルタリングし、上位のフィルタリングをさらに削減します。
B+Treeのディスク構造
リーフディスク構造
FreedomのB+Treeはディスクに格納される。Freedomはページ単位でディスクとやり取りをする。リーフノードもノンリーフノードもページ単位で運ばれ、ディスクにスワイプされる。その構造を以下に示す。

タプル(tuple/item)は、ページ内で固定長のItemPointerと不定長のItemの2つに分割されます。
ItemPointer は、対応する項目の開始オフセットと長さを格納する。また、ItemPointerとItemは図のように中心に向かって伸びるので、固定長でないItemを整理するのに非常に効率的な方法である。
ページにおけるリーフノードとノードノードの違い
leaf と node は page 内の構成は同じであるが、item に含まれる項目に違いがある。Freedomはインデックス付き組織表を使用しているため、下図のようにleafのclusterIndexとsecondaryIndexの項目の表現に違いがあります。

セカンダリインデックス検索では、index-key を介して secondaryIndex で対応する clusterId を検索し、index-key を介して
clusterId は clusterIndex 内の対応する行レコードを見つけます。
ディスクを落としたいので、Freedomはitem内のpagenoに対応するindex-keyをnodeに書き込んでいます。
これにより、ディスクからすべてのインデックス構造を簡単に復元することができます。
ファイル内のB+Tree構成
ページ構造を用いると、メモリ上のデータを1ページ分の大きさで運ぶことができ、また、ページを対応するファイルにリフレッシュすることができます。node.itemのpagenoを使えば、ファイルとメモリ構造の対応付けが簡単にできます。
B+のツリーは、下図のようにディスクファイル内に整理されている。

これに対応する、メモリ上のB+木のマッピング構造を下図に示す。

ファイルページとインメモリページの内容は、dirtyなどインメモリページに特有のフィールドを除いて基本的に同じです。
1つのインデックスに1つのB+ツリー
Freedomでは、各インデックスがB+木であり、レコードの挿入や変更はすべてのB+木に対して行われる。
B+Treeのテスト
ランダムな可変長レコードなどの一連のテストケースを通してB+Treeを挿入・削除することで、非常に奇妙なコーナーケースのいくつかを修正しました。
B+Treeのトドメは
著者はここで最も単純な B+Tree 構造を完成させただけで、同時変更のためのロック機構を追加せず、ダウンタイムなどの壊滅的な状況での一貫性を確保するために B+Tree が操作を行う際のロギングも行っていません。したがって、すべての作業を行ったとしても、高度な同時性と可用性を持つ Bptree まではまだ非常に長い道のりが待っているのです。
メタデータ
テーブルのメタ情報は、テーブルを作成する際に作成されます。作成後、メタ情報は削除され、Freedomが再起動時にテーブル情報を読み込むことができるようになります。各テーブルのメタ情報は1ページ分のスペースしか占めず、なおかつページ構造を再利用し、主にクラスタ化インデックスとセカンダリインデックスの情報を格納する。メタ情報は下図のようにItemに対応する。

もしmybatisにFreedomに関するコードを自動生成させたいなら、Freedomに関するメタ情報を提示するための特定のSQLも実装する必要があります。これは作者の別のプロジェクト、riderで実装されています。原理は以下の図の通りです。

以上の4種類のSQLを実装すると、mybatis-generatorはjdbc経由でFreedomからメタ情報を取得し、コードを自動生成することができます。
トランザクション対応
Freedomは現在同時実行性を保証していないため、トランザクションのサポートには最もシンプルなWALプロトコルのみが使用されています。アトミック性は、redo/undologをログすることによって達成されます。
Redo/Undoログプロトコル形式
Freedomは、変更された操作ごとにログを生成し、変更前の行(undo)と変更後の行(redo)の情報を記録します。undoはロールバックに、redoはダウンタイムの回復に使用されます。その構造は次の図のとおりです。

WALプロトコル
WALプロトコルは理解しやすく、トランザクションがコミットされる前に、現在のトランザクションで生成されたすべてのログレコードをディスクにフラッシュするものである。
Freedomも当然これを行うので、ダウンタイム後にログを経由して全データを復旧させることが可能になります。

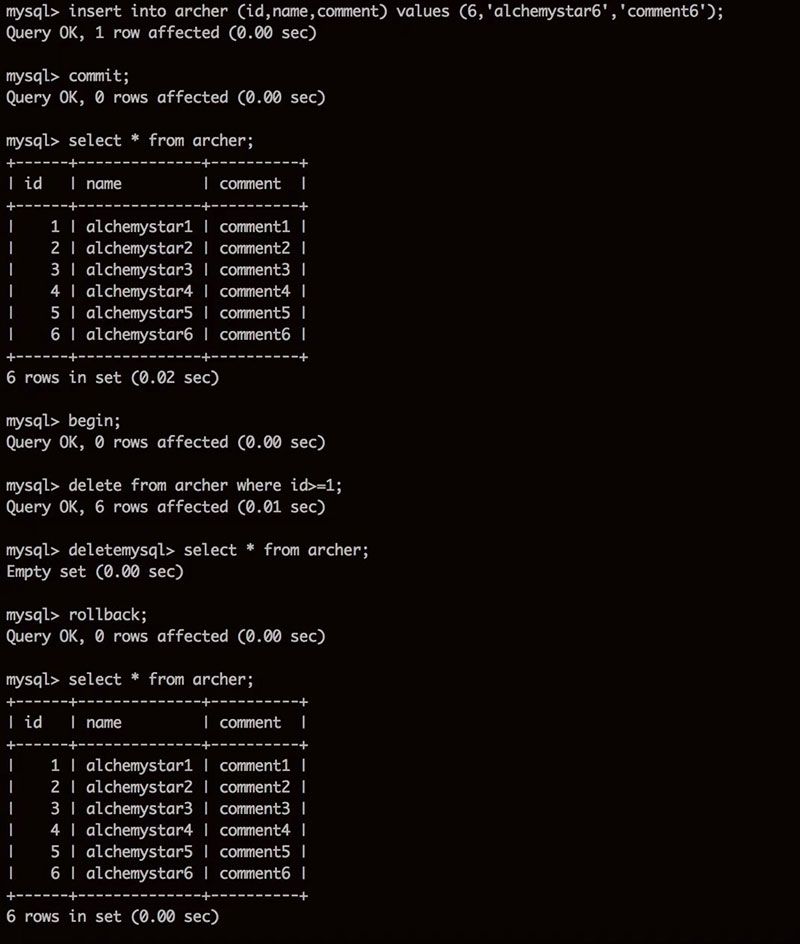
ロールバックの実装
アンドゥはログに記録されるため、トランザクションのロールバックはアンドゥ用のログを通じて直接行うことができる。これは以下の図に示されています。

ダウンタイムリカバリー
フリーダムは、ページがすべてフラッシュされた後にシャットダウンされた場合、ページをロードすることで元のデータを取得することができます。
しかし、kill -9した後など、突然ダウンした場合は、WALプロトコルに記録されているREDO/UNDOログを利用して、再
フリーダムラン
git clone https://github.com/alchemystar/Freedom.git
// デプロイするパッケージがないので、javaエディタ内で行うのが一番簡単な方法です。
alchemystar.freedom.engine.server.mainを実行します。
実際にFreedomを動かしている例です。

ジョインクエリ

削除ロールバック
エピローグ
車輪を作る過程は、最初はとても情熱的で楽しいものでした。しかし、システムが大きく複雑になるにつれ、進歩はどんどん遅くなり、時折、当初のビジョンを覆して再設計し、それに関連するすべてのコードを共同で修正しなければならず、まるで泥沼が深くなっていくかのようでした。ここまでで、ソフトウェアエンジニアリングで最も重要なことは、実は複雑さをコントロールすることなのだと実感しました インターフェイスを常にクリーンでエレガントにデザインすることは、大規模なシステムを実装する上で必要不可欠です。
githubリンク: https://github.com/alchemystar/Freedom
以上、独自のSQL実行エンジンの書き方について詳しく説明しました。SQL実行エンジンの書き方については、Scripting Houseの他の関連記事も参考にしてください
関連
-
テーブル変数によるSQL実行効率低下の記録
-
DataGrip データエクスポート/インポート実装例
-
JetBrains DataGripのインストールと使用に関する詳細なチュートリアル
-
DeepinV20 Mariadbのクイックインストールを詳しくご紹介します。
-
Navicat sqlファイルのインポートとエクスポートを素早く行う方法
-
Navicat for Mac システムチュートリアルのインストールと使用方法
-
Dbeaverを使ったHiveへのリモート接続の詳細方法
-
SQLインジェクションの例とその解決方法
-
SQLリレーショナルモデルの知識まとめ
-
データベースのSQLインジェクションの原理と簡単な紹介
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Djangoプロジェクト最適化データベース運用まとめ
-
MySQLとRedisがデータの一貫性を確保する方法について説明します。
-
Hbaseカラムナーストレージ入門チュートリアル
-
ナビカット15のインストールチュートリアルを超詳しく解説(一番信頼できるのはこれ)
-
SQLyogダウンロード、インストール超詳細チュートリアル(プロテスト永久保存版)
-
データベースキャッシュの最終的な整合性に関する4つのオプション
-
NavicatでMySqlデータベースへの接続が遅い問題
-
CentOS 8.2上のCouchDB 3.3データベースを展開する方法
-
データベースクエリタイムアウト最適化問題の実践記録
-
ユニークSQLの原理と応用を解説