Python 人工知能 人間学習 描画 機械学習モデル作成
今日、データサイエンティストは、機械学習モデルにラベル付きのデータを与えて、ルールを理解させることがよくあります。
このルールを使って、新しいデータのラベルを予測することができる。
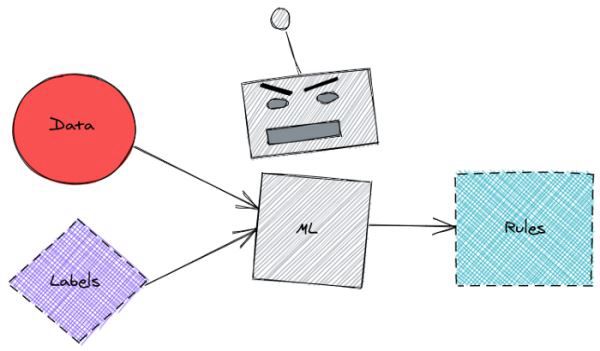
これは便利なのですが、その過程で失われる情報もあるかもしれません。また、ボンネットの中で何が起こっているのか、なぜ機械学習モデルが特定の予測を出しているのかを知ることは困難です。
機械学習モデルがすべてを把握するのではなく、私たちのドメイン知識を使ってデータラベリングのルールを設定する方法はないのでしょうか?
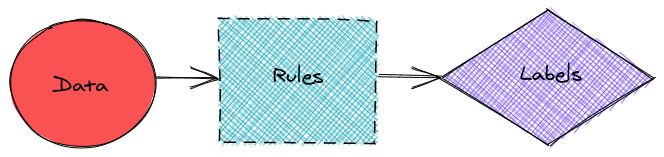
はい、これはヒューマンラーンでも可能です。
ヒューマンラーンとは
human-learnは、インタラクティブなエンジニアリングドローイングやカスタムモデルを使って、データのタグ付けルールを設定することができるツールです。今回は、human-learnを使って、インタラクティブな図面を使ったモデルを作成する方法を紹介します。
human-learnのインストール
pip install human-learn
sklearnのIrisデータを使って、人間学習の仕組みを紹介します。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
# Load data
X, y = load_iris(return_X_y=True, as_frame=True)
X.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# Train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# Concatenate features and labels of the training data
train = pd.concat([X_train, pd.DataFrame(y_train)], axis=1)
train
インタラクティブな描画
human-learnでは、データセットをプロットした後、エンジニアリングプロットを使ってモデルに変換することができます。これがどのように便利かを示すために、次のようにデータセットの散布図を作成することを想像してみてください。
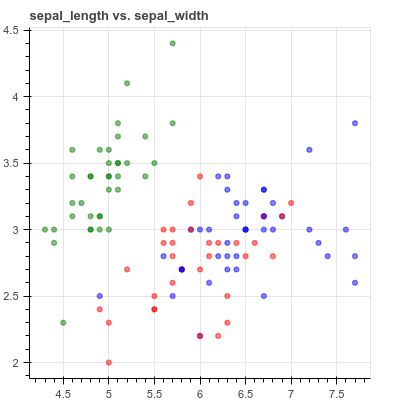
上の図を見ると、以下のように3つの領域に分かれていることがわかります。
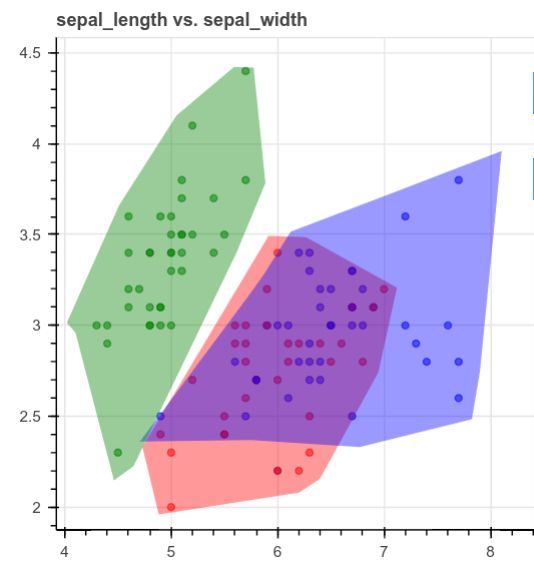
ただ、グラフをルールとして書いて関数に落とし込むのは難しいかもしれませんし、human-learnのインタラクティブな描画は重宝しそうですね。
from hulearn.experimental.interactive import InteractiveCharts
charts = InteractiveCharts(train, labels='target')
charts.add_chart(x='sepal_length', y='sepal_width')
- アクションフィギュア01
描画方法。ダブルクリックで多角形の描画を開始します。その後、クリックでポリゴンの辺を作成します。もう一度ダブルクリックすると、現在のポリゴンの描画を停止します。
他の列も同じようにします。
charts.add_chart(x='petal_length', y='petal_width')
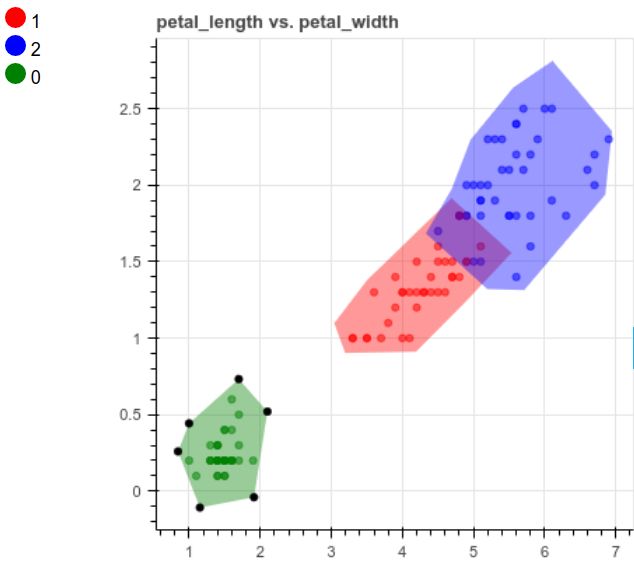
モデルを作成し、予測を行う
データセットのマッピングが完了したら、以下の方法でモデルを作成します。
from hulearn.classification import InteractiveClassifier
model = InteractiveClassifier(json_desc=charts.data())
preds = model.fit(X_train, y_train).predict_proba(X_train)
print(preds.shape) # Output: (150, 3)
かっこいい エンジニアリンググラフをInteractiveClassifierクラスにフィードし、fitやpredict_probaといったsklearnモデルのフィットに類似したメソッドを使用します。
predの最初の5行を見てみましょう。
print('Classes:', model.classes_)
print('Predictions:\n', preds[:5, :])
"""Output
Classes: [1, 2, 0]
Predictions:
[[5.71326574e-01 4.28530630e-01 1.42795945e-04]
[2.00079952e-01 7.99720168e-01 1.99880072e-04]
[2.00079952e-01 7.99720168e-01 1.99880072e-04]
[2.49812641e-04 2.49812641e-04 9.99500375e-01]
[4.99916708e-01 4.99916708e-01 1.66583375e-04]]
"""
predict_probaは,あるサンプルが特定のラベルを持つ確率を与えることに注意することが重要です。例えば、最初の予測値である [5.71326574e-01 4.28530630e-01 1.42795945e-04] は、サンプルがラベル1を持つ確率は57.13%、サンプルがラベル2を持つ確率は42.85%、サンプルがラベル2である確率は 0.014% サンプルはラベル0であることを表しています。
新しいデータを予測する
# Get the first sample of X_test
new_sample = new_sample = X_test.iloc[:1]
# Predict
pred = model.predict(new_sample)
real = y_test[:1]
print("The prediction is", pred[0])
print("The real label is", real.iloc[0])
結果の解釈
その予測に基づいてモデルがどのように予測するかを見るために、新しいサンプルを視覚化してみましょう。
def plot_prediction(prediction: int, columns: list):
"""Plot new sample
Parameters
----------
prediction : int
prediction of the new sample
columns : list
Features to create a scatter plot
"""
index = prediction_to_index[prediction]
col1, col2 = columns
plt.figure(figuresize=(12, 3))
plt.scatter(X_train[col1], X_train[col2], c=preds[:, index])
plt.plot(new_sample[col1], new_sample[col2], 'ro', c='red', label='new_sample')
plt.xlabel(col1)
plt.ylabel(col2)
plt.title(f"Label {model.classes_[index]}")
plt.colorbar()
plt.legend()
上記の関数を使って、新しいサンプルを、サンプルのポイントが0とマークされる確率で色付けされたpetal_lengthとpetal_widthプロット上にプロットします。
plot_prediction(0, columns=['petal_length', 'petal_width'])
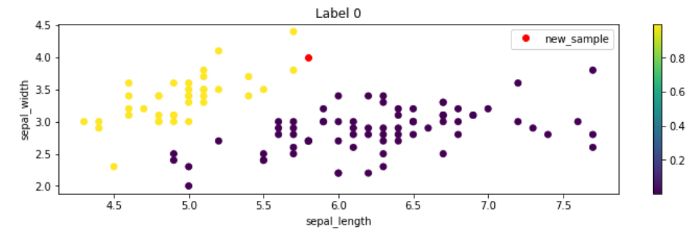
これは他の列でも同様で、赤い点は黄色い点が多い領域にあることがわかります!また、赤い点は、黄色い点が多い領域にあることがわかります。これは、モデルが新しいサンプルのラベルが0であると予測した理由を説明しています。
テストデータの予測・評価
では、このモデルを使ってテストデータ中の全サンプルを予測し、その性能を評価してみましょう。混同行列を用いて評価を開始する。
from sklearn.metrics import confusion_matrix, f1_score
predictions = model.predict(X_test)
confusion_matrix(y_test, predictions, labels=[0,1,2])
array([[13, 0, 0],
[ 0, 15, 1],
[ 0, 0, 9]])
また、F1スコアを使って評価することも可能です。
f1_score(y_test, predictions, average='micro')
まとめ
私たちは、データセットをプロットすることで、データにラベル付けするルールを生成する方法を学びました。これは、機械学習モデルを完全に排除するのではなく、データの処理にある種の人間の監視を加えるべきだということです。
上記は、Pythonの人工知能の詳細である人間がプロットを作成する機械学習モデルを学ぶことができ、人間がプロットを作成する機械学習モデルの詳細については、スクリプトハウスの他の関連記事に注意を払うください
関連
-
[解決済み】Python Error: "ValueError: need more than 1 value to unpack" (バリューエラー:解凍に1つ以上の値が必要です
-
[解決済み】ZeroDivisionErrorの取得:Pythonのfloat除算
-
[解決済み】 _tkinter.TclError: 表示名がなく、$DISPLAY環境変数もない。
-
[解決済み】Python 二項係数
-
[解決済み] インテル® MKL FATAL ERROR。mkl_intel_thread.dllをロードできません。
-
[解決済み] 複数の条件を指定してwhileループを行う方法
-
[解決済み] PythonでPDFを特定のプリンタに無音印刷する
-
[解決済み] statsmodels.api が MissingDataError を返す:多変量回帰の適合時に exog に inf または nans が含まれる
-
[Python】PandasのDataFrame基本関数 (full)
-
Python3dの描画 mpl_toolkits.mplot3d
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] 'int'オブジェクトに'__getitem__'属性がない。
-
[解決済み] TKinterのボタンの無効化/有効化
-
[解決済み] Pythonを使ったディレクトリ内のファイル数の数え方
-
[解決済み] _csv.Error: iterator should return strings, not bytes (did you open file in text mode?) [duplicate].
-
[解決済み] TypeError: 'str' と 'list' オブジェクトをメールに連結することはできません。
-
[解決済み] デーモン作成時にダブルフォークを行う理由は何ですか?
-
[解決済み] Project Euler #3 with python - MOST EFFICIENT METHOD [クローズド].
-
[解決済み] LEFT JOIN Django ORM
-
pycharm python: pep 8: 2つの空行を期待したが、1つ見つかった。
-
python のエラーです。TypeError: 文字列のインデックスは整数でなければならない