Redisの文字列はどのように実装されているか
前文
文字列は日常の開発でよく使われますが、Redisの場合、キーと値のペアのキーが文字列で、値が文字列です。例えば、Redisで顧客メッセージを書くと、名前、性別、好みなどが記録されます。
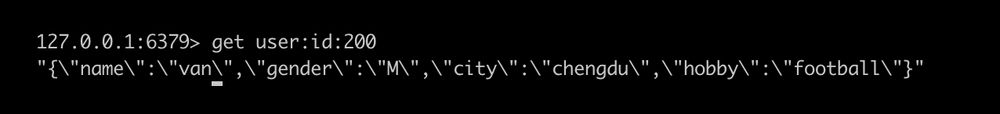
Redisのような文字列が多用されるインメモリデータベースでは、文字列は以下のように設計されています。
1. 1. リッチで効率的な文字列操作(追加、コピー、比較など)をサポートします。
2. バイナリデータ保存機能
3. 3. メモリのオーバーヘッドを可能な限り節約できる
C言語ライブラリでは、文字列操作のためにchar*のような文字配列が用意されています。Cライブラリの文字列の使い方は一般的ですが、問題がないわけではありません。頻繁に空間の生成とチェックが必要であり、実際のプロジェクトでは時間がかかることがあります。そこで、Redisは文字列を表現するためにSimple Data Strings (SDS)を設計しました。これにより、元のC言語と比較して文字列操作の効率が向上し、バイナリ形式もサポートされます。以下、Redisの文字列がどのように実装されているかを紹介します。
なぜchar*を使用しないのか?
まず、char*文字配列の構造を見てみましょう。実は、連続したメモリ空間を開いて各文字を順番に格納し、最後の文字が" \0" で文字列の終わりを意味するという非常にシンプルなものです。Cライブラリの文字列操作関数は、" \0" を調べて文字列の終わりを判定しているのです。例えば、strlen関数は、文字配列の各文字を反復してカウントし、カウントの終端である" \0" に出会うまでカウントし、その結果を返します。以下は、" \0" の終端文字が文字列の長さにどのように影響するかを確認するためのコードです。
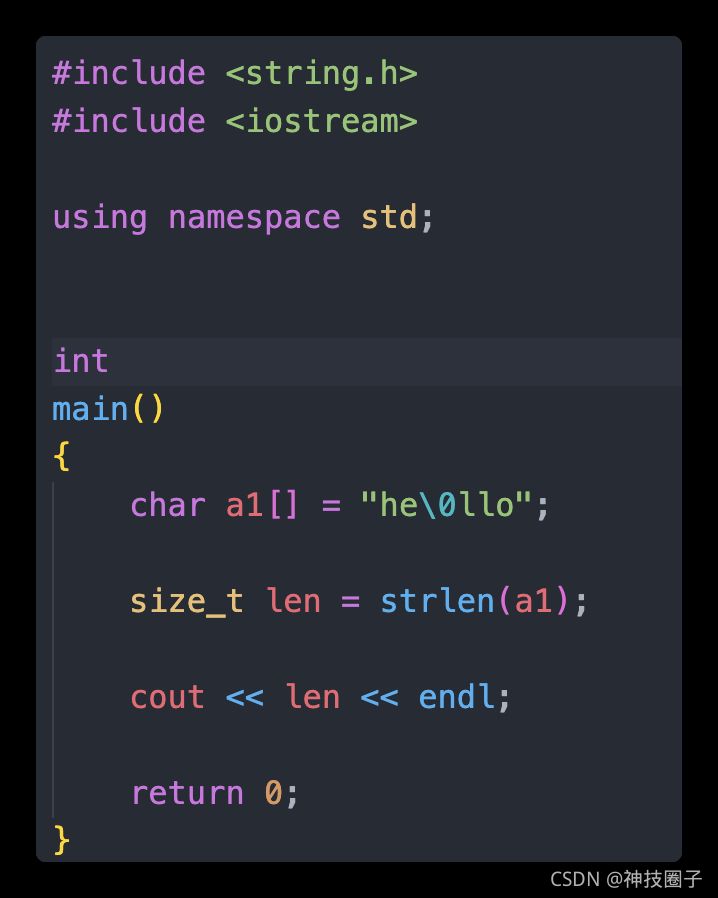
このコードを実行すると、次のようになります。

a1 の文字数が 2 文字であることを示す。これは、he の後に "\0" があるため、文字列が "\0" で終わってしまうためで、文字列自体の中に "\0" があると、データが "\0" で切り捨てられ、これでは、he の後に "\0" があることを示すことができない、という問題が発生します。 任意のバイナリデータの保存 は、その
従来の設計操作の高い複雑性
上記のように任意のバイナリデータを保存できないことに加え、演算の複雑さも相当なものである。例えば、C言語でよく使われるstrlen関数は、文字列の長さを得るために、文字配列のすべての文字を繰り返し処理しなければならない。そのため、時間計算量はO(n)となる。もう一つの一般的な関数strcatは、strlen関数と同じように、まず文字列を走査して対象文字列の終端を求め、対象文字列の終端に元文字列を付加しますが、対象文字列に十分な空きがあるかどうかも確認しています。そのため、開発者はこの関数を呼び出す際に、対象の文字列に十分なスペースがあることを確認する必要があり、そうでない場合は動的にスペースを要求する必要がある。これは、時間的に複雑なだけでなく、運用面でも複雑である。
SDSの設計
RedisはC言語標準の文字列操作関数をできるだけ再利用するように設計されており、Redisは実際のデータを保持するために文字配列の使用を維持したままSDSデータ構造を設計しています。
まず、SDS構造体には文字配列buf[]が含まれ、さらにSDS構造体には3つのメタデータが含まれる。メタデータlenとallocはSDSの種類を定義している。
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings.
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
図解で説明すると
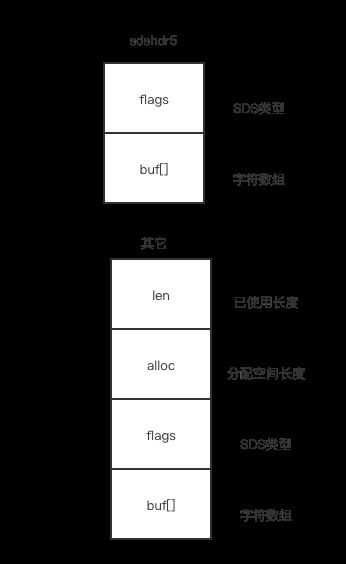
コード内にエイリアスが定義されている
typedef char *sds;
つまり、SDSは本質的には文字配列のままであり、文字配列の上に追加のメタデータが乗っているだけで、Redisは文字配列を使用する際にsdsというエイリアスを直接使用します。
SDSの効率的な運用
sdsの作成
Redisはsdsnewlen関数を呼び出してsdsを作成します。sedsnewlenを例にして、以下のコードを書いてみましょう。
hisds sdsnewlen(const void *init, size_t initlen) {
//pointer to the SDS structure
void *sh;
//variable of type sds, which is an alias of char*
sds s;
//get the type of SDS based on size
char type = hi_sdsReqType(initlen);
/* Empty strings are usually created in order to append. use type 8
Use type 8. * since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
// allocate memory for the newly created sds structure
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) return NULL;
if (!init)
memset(sh, 0, hdrlen+initlen+1);
// point to the buf array in the SDS structure, sh points to the starting position of the SDS structure, hdrlen indicates the length of the metadata
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
//initialize len,alloc according to type
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << HI_SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
// copy the string to the sds variable s
memcpy(s, init, initlen);
//add "\0" at the end of the string variable to indicate the end of the string
s[initlen] = '\0';
return s;
}
この関数の主な実行内容は以下の通りです。
1. 初期化長に応じたSDSタイプを取得します。初期化長initlenが0であれば、一般的に追記操作を行うものと考え、SDSタイプをSDS_TYPE_8とする
2. 2. 新しく作成されたSDS構造体に対して、メタデータ長+buf長+文字列終端記号" \0" のメモリ空間を割り当てます。
3. 3. SDS タイプに応じてメタデータの len と alloc を初期化する。
4. 文字列をsdsにコピーする
文字配列のスプライシング
sds構造体は占有容量と割り当て容量を記録しているので、従来のC言語文字列よりも効率的です。Redisの文字列追加関数、sdscatlenを使って見てみましょう。コードは以下の通りです。
sds sdscatlen(sds s, const void *t, size_t len) {
//Get the length of the target string
size_t curlen = sdslen(s);
//determine if new space needs to be added based on append length and target string length
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
// copy the data of length len from the source string t to the end of the target string
memcpy(s+curlen, t, len);
//set the latest length of the target string
sdssetlen(s, curlen+len);
//after the copy is done, add "\0" at the end of the string;
s[curlen+len] = '\0';
return s;
}
この関数は、ターゲット文字列s、ソース文字列t、追加する長さlenの3つのパラメータを持っています。このコードは次のように実行されます。
1. まず対象の文字列の長さを取得し、次にsdsMakeRoomFor関数を呼び出して、対象の文字列に新たにスペースを追加するかどうかを判断し、対象の文字列に文字列を追記するのに十分なスペースがあるようにします
2. 2. 文字列を追加するのに十分なスペースがあることを確認した後、ソース文字列からターゲット文字列に指定された長さlenのデータを追加する。
3. 対象文字列の最新の長さを設定する
長さフェッチ
このコードでは、関数sdslenが使用した文字配列の長さを記録するため、Cライブラリのように文字列を繰り返し処理する必要がなく、使用した文字列を操作するオーバーヘッドを大幅に削減することができます。この関数のコードを以下に示す。
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
これにより、時間計算量はO(1)にまで低下します。この関数は、s[-1]からフラグを取得してSDS_HDRマクロ関数を呼び出すという杜撰な操作をしています。このマクロ関数の定義を見てみましょう。
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
ここで、##は2つのトークンを1つのトークンに連結するために使われるので、パラメータを追加すると、プリコンパイル段階で次のように置き換えられることになります。
SDS_HDR(8,s);
((struct sdshdr8 *)((s)-(sizeof(struct sdshdr8))))
構造体のサイズから文字配列のアドレスを引いて構造体の先頭アドレスを取得し、len属性に直接アクセスします。
メモリ空間の事前割り当て
また、コード内ではsdsMakeRoomFor関数が使われており、縫い合わせる前に文字列を展開する必要があるかどうかをチェックし、展開する必要がある場合は事前に領域を確保するようになっています。この設計の利点は、開発中に対象の文字列を拡張し忘れて操作に失敗することを避けられることだ。例えば、strcpy(char* dst, const char* dst)では、srcの長さがdstの長さより大きい場合に、何もチェックしないとメモリオーバーフローが発生することになります。そのコードを以下に示します。
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
//Get the space currently available in sds
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
size_t usable;
// enough free space, no need to expand
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
assert(newlen > len); /* Catch size_t overflow */
// If the length of the new character array is less than SDS_MAX_PREALLOC
// allocate 2 times the required length
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
// otherwise allocate the new length plus the length of SDS_MAX_PREALLOC
else
newlen += SDS_MAX_PREALLOC;
//Retrieve the SDS type
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
/* Don't use type 5: the user is appending to the string and type 5 is * not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation.
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
assert(hdrlen + newlen + 1 > len); /* Catch size_t overflow */
if (oldtype==type) {
newsh = s_realloc_usable(sh, hdrlen + newlen + 1, &usable);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/ / if the header size changes just move the character array forward without using realloc
newsh = s_malloc_usable(hdrlen+newlen+1, &usable);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
usable = usable-hdrlen-1;
if (usable > sdsTypeMaxSize(type))
usable = sdsTypeMaxSize(type);
//Update SDS capacity
sdssetalloc(s, usable);
return s;
}
ここで、SDS_MAX_PREALLOCの長さは1024*1024です。
#define SDS_MAX_PREALLOC (1024*1024)
省メモリ設計
SDS構造体は、前述のように文字列型を示すメタデータフラグを持っています。sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64の5種類で、主な違いは、その文字配列の既存の長さlenと割り当て空間allocです。
では、sdshdr16を例にとると、次のように定義されています。
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
既存の長さ len と割り当てられた領域 alloc はともに uint16_t 型であることがわかります。uint16_t は 2 バイトを占有する 16 ビットの符号なし整数です。文字列型がsdshdr16の場合、最大長2^16-1バイトの文字の配列が格納されます。そして、他の3つの sdshdr8,sdshdr32,sdshdr64 などは、それぞれ uin8_t, uin32_t, uint64_t で、len と alloc の2つのメタデータはそれぞれ1バイト、4バイト、8バイトを占有する。
実は、構造体ヘッダを変えて設計したのは、異なるサイズの文字列を柔軟に保存することで、メモリ空間を効率的に節約するためです。構造体ヘッダは、異なるサイズの文字列を保存する際に異なるメモリ空間を占有するため、小さな文字列を保存する際にも、より少ないメモリしか占有しません。
Redisは、さまざまなタイプの構造体ヘッダを設計するだけでなく、コンパイルの最適化によってメモリスペースを節約しています。例えば、上記のsdshdr16のコードでは、__attribute__ ((
パック
)) これは、コンパイラにコンパクトな方法でメモリを割り当てるように指示するためのものです。デフォルトでは、コンパイラは16バイトのアライメントに従って変数にメモリーを割り当てます。つまり、16バイトにならない変数は、コンパイラが同様に16バイトを割り当てるということです。
例を挙げてみましょう。
#include <string.h>
#include <iostream>
using namespace std;
typedef struct MyStruct
{
char a;
int b;
} MyStruct;
int
main()
{
cout << sizeof(MyStruct) << endl;
return 0;
}
charは1バイト、intは4バイトですが、8バイトで出力されるので、余分な3バイトは無駄になってしまいます。ここで、__attribute__を適用します(( パック )) 属性を使って構造体を定義し、コンパイラが実際に使用するバイト数と同じだけのバイト数を割り当てられるようにします。この属性を追加するためにコードを修正しましょう。コードは次のようになります。
#include <string.h>
#include <iostream>
using namespace std;
typedef struct MyStruct
{
char a;
int b;
} __attribute__ ((__packed__))MyStruct;
int
main()
{
cout << sizeof(MyStruct) << endl;
return 0;
}
このコードを実行すると5となり、コンパイラがコンパクトなメモリ割り当てを行っていることが分かります。開発時にメモリのオーバーヘッドを節約するために、__attribute__ (( パック )) 属性を使用することで、開発時にメモリのオーバーヘッドを節約することができます。
Redisの文字列がどのように実装されているかについてのこの記事は終わりです。Redis文字列の詳細については、Script Houseの過去の記事を検索するか、以下の記事を引き続きご覧ください。
関連
-
RedisTemplatを使った簡単な分散ロックの実装の話
-
redis分散ロックについて解説(redis分散ロックの最適化処理とRedissonの利用について)
-
SpringBootのRedis連携のアイデア解説
-
Redisのkeysコマンドの遅さ
-
インタビューFAQです。Redisキャッシュとデータベース間のデータ整合性を確保する方法
-
Redis 高効率化の理由とデータ構造の解析
-
redisを使ってnearly peopleの機能を実装する
-
Redisデータ永続化技術解説
-
SpringBootがRedisの分散ロックを利用して並行処理の問題を解決することについて
-
Redisの分散ロックについて簡単に説明します
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
redisキャッシュストレージのセッション原理機構
-
redis の RedissonLock が待ちロックを実装する方法
-
redisプラグインbloom-filterをcentosにインストールする方法
-
Redisで緯度・経度座標データを簡単に扱う方法
-
redis クラスタの実装は同じプレフィックスを持つキーをクリーンアップします。
-
redis分散ロック最適化の実装
-
Redisの高同期スパイクを防ぐために、ソースコードソリューションを売られすぎ
-
RedisClusterが16,384個のスロットを持つ設計になっている理由
-
Redis の例外と使用法のまとめ
-
インストール後、Redis-cliが動作しない(redis-cli: コマンドが見つからない)。