Linuxでのmemcpyのパフォーマンスの悪さ
質問
最近、新しいサーバーをいくつか購入したのですが、memcpy のパフォーマンスが低下しています。memcpy のパフォーマンスは、私たちのラップトップと比較して、サーバー上で 3 倍遅くなります。
サーバーのスペック
- シャーシとモボ スーパーマイクロ1027GR-TRF
- CPU: 2x Intel Xeon E5-2680 @ 2.70 Ghz
- メモリ: 8x 16GB DDR3 1600MHz
編集: 私はまた、少し高いスペックの別のサーバーでテストしており、上記のサーバーと同じ結果を見ています。
サーバー 2 のスペック
- シャーシとモボ スーパーマイクロ10227GR-TRFT
- CPU: 2x Intel Xeon E5-2650 v2 @ 2.6 Ghz
- メモリ: 8x 16GB DDR3 1866MHz
ノートパソコンのスペック
- シャーシ Lenovo W530
- CPU 1x Intel Core i7 i7-3720QM @ 2.6Ghz
- メモリ 4x 4GB DDR3 1600MHz
オペレーティング システム
$ cat /etc/redhat-release
Scientific Linux release 6.5 (Carbon)
$ uname -a
Linux r113 2.6.32-431.1.2.el6.x86_64 #1 SMP Thu Dec 12 13:59:19 CST 2013 x86_64 x86_64 x86_64 GNU/Linux
コンパイラ (すべてのシステムで)
$ gcc --version
gcc (GCC) 4.6.1
また、@stefan の提案により gcc 4.8.2 でのテストも行いました。コンパイラ間の性能差はありませんでした。
テストコード 以下のテストコードは、私がプロダクションコードで見ている問題を複製するための定型的なテストです。私はこのベンチマークが単純であることを知っていますが、それは私たちの問題を悪用し、特定することができました。このコードでは、2つの1GBのバッファを作成し、memcpyの呼び出しのタイミングを合わせて、それらのバッファ間でmemcpysを行っています。./big_memcpy_test [SIZE_BYTES] を使用して、コマンドラインで別のバッファサイズを指定することができます。
#include <chrono>
#include <cstring>
#include <iostream>
#include <cstdint>
class Timer
{
public:
Timer()
: mStart(),
mStop()
{
update();
}
void update()
{
mStart = std::chrono::high_resolution_clock::now();
mStop = mStart;
}
double elapsedMs()
{
mStop = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds elapsed_ms =
std::chrono::duration_cast<std::chrono::milliseconds>(mStop - mStart);
return elapsed_ms.count();
}
private:
std::chrono::high_resolution_clock::time_point mStart;
std::chrono::high_resolution_clock::time_point mStop;
};
std::string formatBytes(std::uint64_t bytes)
{
static const int num_suffix = 5;
static const char* suffix[num_suffix] = { "B", "KB", "MB", "GB", "TB" };
double dbl_s_byte = bytes;
int i = 0;
for (; (int)(bytes / 1024.) > 0 && i < num_suffix;
++i, bytes /= 1024.)
{
dbl_s_byte = bytes / 1024.0;
}
const int buf_len = 64;
char buf[buf_len];
// use snprintf so there is no buffer overrun
int res = snprintf(buf, buf_len,"%0.2f%s", dbl_s_byte, suffix[i]);
// snprintf returns number of characters that would have been written if n had
// been sufficiently large, not counting the terminating null character.
// if an encoding error occurs, a negative number is returned.
if (res >= 0)
{
return std::string(buf);
}
return std::string();
}
void doMemmove(void* pDest, const void* pSource, std::size_t sizeBytes)
{
memmove(pDest, pSource, sizeBytes);
}
int main(int argc, char* argv[])
{
std::uint64_t SIZE_BYTES = 1073741824; // 1GB
if (argc > 1)
{
SIZE_BYTES = std::stoull(argv[1]);
std::cout << "Using buffer size from command line: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
else
{
std::cout << "To specify a custom buffer size: big_memcpy_test [SIZE_BYTES] \n"
<< "Using built in buffer size: " << formatBytes(SIZE_BYTES)
<< std::endl;
}
// big array to use for testing
char* p_big_array = NULL;
/////////////
// malloc
{
Timer timer;
p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
if (p_big_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " returned NULL!"
<< std::endl;
return 1;
}
std::cout << "malloc for " << formatBytes(SIZE_BYTES) << " took "
<< timer.elapsedMs() << "ms"
<< std::endl;
}
/////////////
// memset
{
Timer timer;
// set all data in p_big_array to 0
memset(p_big_array, 0xF, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memset for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
}
/////////////
// memcpy
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memcpy test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memcpy FROM p_big_array TO p_dest_array
Timer timer;
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memcpy for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
/////////////
// memmove
{
char* p_dest_array = (char*)malloc(SIZE_BYTES);
if (p_dest_array == NULL)
{
std::cerr << "ERROR: malloc of " << SIZE_BYTES << " for memmove test"
<< " returned NULL!"
<< std::endl;
return 1;
}
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
// time only the memmove FROM p_big_array TO p_dest_array
Timer timer;
// memmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
doMemmove(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
double elapsed_ms = timer.elapsedMs();
std::cout << "memmove for " << formatBytes(SIZE_BYTES) << " took "
<< elapsed_ms << "ms "
<< "(" << formatBytes(SIZE_BYTES / (elapsed_ms / 1.0e3)) << " bytes/sec)"
<< std::endl;
// cleanup p_dest_array
free(p_dest_array);
p_dest_array = NULL;
}
// cleanup
free(p_big_array);
p_big_array = NULL;
return 0;
}
ビルドするCMakeファイル
project(big_memcpy_test)
cmake_minimum_required(VERSION 2.4.0)
include_directories(${CMAKE_CURRENT_SOURCE_DIR})
# create verbose makefiles that show each command line as it is issued
set( CMAKE_VERBOSE_MAKEFILE ON CACHE BOOL "Verbose" FORCE )
# release mode
set( CMAKE_BUILD_TYPE Release )
# grab in CXXFLAGS environment variable and append C++11 and -Wall options
set( CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x -Wall -march=native -mtune=native" )
message( INFO "CMAKE_CXX_FLAGS = ${CMAKE_CXX_FLAGS}" )
# sources to build
set(big_memcpy_test_SRCS
main.cpp
)
# create an executable file named "big_memcpy_test" from
# the source files in the variable "big_memcpy_test_SRCS".
add_executable(big_memcpy_test ${big_memcpy_test_SRCS})
テスト結果
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 1
Laptop 2 | 0 | 180 | 120 | 1
Server 1 | 0 | 306 | 301 | 2
Server 2 | 0 | 352 | 325 | 2
ご覧のように、サーバー上の memcpys と memsets は、ラップトップ上の memcpys と memsets よりもはるかに遅いのです。
さまざまなバッファ サイズ
私は 100MB から 5GB までのバッファを試しましたが、すべて同じような結果でした (サーバはラップトップより遅い)。
NUMA アフィニティ
NUMA でパフォーマンスの問題がある人々について読んだので、私は numactl を使用して CPU とメモリのアフィニティを設定してみましたが、結果は同じままでした。
サーバー NUMA ハードウェア
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 65501 MB
node 0 free: 62608 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 65536 MB
node 1 free: 63837 MB
node distances:
node 0 1
0: 10 21
1: 21 10
ラップトップ NUMA ハードウェア
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7
node 0 size: 16018 MB
node 0 free: 6622 MB
node distances:
node 0
0: 10
NUMAアフィニティの設定
$ numactl --cpunodebind=0 --membind=0 ./big_memcpy_test
これを解決するどんな助けも非常に感謝されます。
編集: GCC オプション
コメントに基づいて、私は異なるGCCオプションでコンパイルを試しました。
march と -mtune を native に設定してコンパイルしてみました。
g++ -std=c++0x -Wall -march=native -mtune=native -O3 -DNDEBUG -o big_memcpy_test main.cpp
結果 全く同じ性能(改善なし)
O3ではなく-O2でコンパイルする
g++ -std=c++0x -Wall -march=native -mtune=native -O2 -DNDEBUG -o big_memcpy_test main.cpp
結果 全く同じ性能(改善なし)
編集:NULLページを回避するためにmemsetを0ではなく0xFを書き込むように変更しました。
0以外の値でmemsetしても改善しない(今回は0xFを使用)。
編集:Cachebenchの結果
私のテストプログラムが単純すぎることを除外するために、私は本物のベンチマークプログラムである LLCacheBench をダウンロードしました ( http://icl.cs.utk.edu/projects/llcbench/cachebench.html )
アーキテクチャの問題を避けるために、各マシンで別々にベンチマークを構築しました。以下は私の結果です。
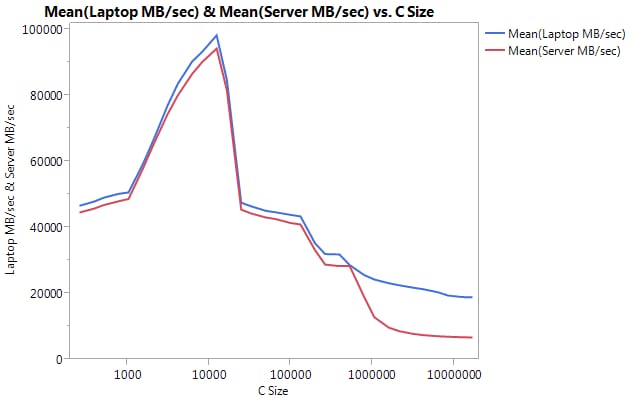
非常に大きな違いは、より大きなバッファ サイズでのパフォーマンスであることに注目してください。テストした最後のサイズ (16777216) は、ラップトップでは 18849.29 MB/秒、サーバーでは 6710.40 MB/ 秒で実行されました。これは、約3倍の性能差です。また、サーバーのパフォーマンスの落ち込みがラップトップよりもはるかに急であることに気づくでしょう。
編集: memmove() はサーバー上の memcpy() より 2 倍高速です。
いくつかの実験に基づき、私はテストケースで memcpy() の代わりに memmove() を使用してみて、サーバー上で 2 倍の改善を発見しました。ラップトップ上の memmove() は memcpy() よりも遅く実行されますが、奇妙なことに、サーバー上の memmove() と同じ速度で実行されます。これは、なぜmemcpyがそんなに遅いのか、という疑問を投げかけるものです。
memcpyと一緒にmemmoveをテストするためにコードを更新しました。memmove()をインラインのままにしておくとGCCが最適化してmemcpy()と全く同じ動作をするため、関数の中にラップしなければなりませんでした(GCCがmemcpyに最適化したのは、場所が重複しないことを知っていたからだと思われます)。
更新された結果
Buffer Size: 1GB | malloc (ms) | memset (ms) | memcpy (ms) | memmove() | NUMA nodes (numactl --hardware)
---------------------------------------------------------------------------------------------------------
Laptop 1 | 0 | 127 | 113 | 161 | 1
Laptop 2 | 0 | 180 | 120 | 160 | 1
Server 1 | 0 | 306 | 301 | 159 | 2
Server 2 | 0 | 352 | 325 | 159 | 2
編集: Naive Memcpy
Salgarからの提案に基づき、私は自分自身のナイーブmemcpy関数を実装し、それをテストしました。
素朴なmemcpyのソース
void naiveMemcpy(void* pDest, const void* pSource, std::size_t sizeBytes)
{
char* p_dest = (char*)pDest;
const char* p_source = (const char*)pSource;
for (std::size_t i = 0; i < sizeBytes; ++i)
{
*p_dest++ = *p_source++;
}
}
memcpy()と比較したナイーブMemcpyの結果
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop 1 | 113 | 161 | 160
Server 1 | 301 | 159 | 159
Server 2 | 325 | 159 | 159
編集:アセンブリ出力
シンプルなmemcpyのソース
#include <cstring>
#include <cstdlib>
int main(int argc, char* argv[])
{
size_t SIZE_BYTES = 1073741824; // 1GB
char* p_big_array = (char*)malloc(SIZE_BYTES * sizeof(char));
char* p_dest_array = (char*)malloc(SIZE_BYTES * sizeof(char));
memset(p_big_array, 0xA, SIZE_BYTES * sizeof(char));
memset(p_dest_array, 0xF, SIZE_BYTES * sizeof(char));
memcpy(p_dest_array, p_big_array, SIZE_BYTES * sizeof(char));
free(p_dest_array);
free(p_big_array);
return 0;
}
アセンブリの出力です。これはサーバーとラップトップの両方で全く同じです。スペースを節約するため、両方は貼り付けていません。
.file "main_memcpy.cpp"
.section .text.startup,"ax",@progbits
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB25:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movl $1073741824, %edi
pushq %rbx
.cfi_def_cfa_offset 24
.cfi_offset 3, -24
subq $8, %rsp
.cfi_def_cfa_offset 32
call malloc
movl $1073741824, %edi
movq %rax, %rbx
call malloc
movl $1073741824, %edx
movq %rax, %rbp
movl $10, %esi
movq %rbx, %rdi
call memset
movl $1073741824, %edx
movl $15, %esi
movq %rbp, %rdi
call memset
movl $1073741824, %edx
movq %rbx, %rsi
movq %rbp, %rdi
call memcpy
movq %rbp, %rdi
call free
movq %rbx, %rdi
call free
addq $8, %rsp
.cfi_def_cfa_offset 24
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 16
popq %rbp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE25:
.size main, .-main
.ident "GCC: (GNU) 4.6.1"
.section .note.GNU-stack,"",@progbits
プログレス!!! asmlib
tbensonの提案に基づき、私は、"asmlib "を使用して実行することを試みました。 asmlib バージョンの memcpy を実行してみました。私の結果は最初は悪かったのですが、SetMemcpyCacheLimit() を 1GB (バッファのサイズ) に変更したら、私の単純な for ループと同等の速度で実行できるようになりました!
悪いニュースは、asmlib版のmemmoveはglibc版より遅く、現在300msマークで動作しています(glibc版のmemcpyと同程度)。奇妙なことに、ラップトップで SetMemcpyCacheLimit() を大きな数に設定すると、パフォーマンスが低下します...。
以下の結果では、SetCache でマークされた行は、SetMemcpyCacheLimit が 1073741824 に設定されています。SetCache がない結果は、SetMemcpyCacheLimit() を呼び出しません。
asmlibの関数を使用した結果です。
Buffer Size: 1GB | memcpy (ms) | memmove(ms) | naiveMemcpy()
------------------------------------------------------------
Laptop | 136 | 132 | 161
Laptop SetCache | 182 | 137 | 161
Server 1 | 305 | 302 | 164
Server 1 SetCache | 162 | 303 | 164
Server 2 | 300 | 299 | 166
Server 2 SetCache | 166 | 301 | 166
キャッシュの問題に傾き始めていますが、何が原因なのでしょうか?
どのように解決するのですか?
[私はこれをコメントにしたいのですが、そうするほど評判がよくありません。]
私は同様のシステムを持っており、同様の結果を見ていますが、いくつかのデータポイントを追加することができます。
-
ナイーブの方向を逆にすると
memcpy(に変換する)。*p_dest-- = *p_src--に変換する)場合、順方向の場合よりもはるかに悪いパフォーマンスが得られるかもしれません(私の場合、〜637ms)。変更があったのはmemcpy()を呼び出す際にいくつかのバグを露呈しました。memcpyをオーバーラップするバッファで呼び出す場合のバグをいくつか公開しました ( http://lwn.net/Articles/414467/ ) のバージョンに切り替えたことで問題が発生したと考えています。memcpyを後方で動作するバージョンに切り替えたことが原因だと思います。つまり、後方コピーと前方コピーで説明できるのはmemcpy()/memmove()の格差がある。 -
非一時的なストアは使わない方が良さそうです。 多くの最適化された
memcpy()の実装では、大きなバッファ(つまり最終レベルのキャッシュより大きい)には非一時的なストア(キャッシュされない)に切り替えています。私は Agner Fog のバージョンの memcpy をテストしました ( http://www.agner.org/optimize/#asmlib ) のバージョンとほぼ同じ速度であることがわかりました。glibc. しかしasmlibは関数 (SetMemcpyCacheLimit) があり、非一時的な保存が使用される閾値を設定することができます。その制限を8GB(または1GiBバッファよりちょうど大きい)に設定して非一時的なストアを回避すると、私のケースではパフォーマンスが2倍になりました(時間は176msに短縮)。もちろん、これは前方向の素朴なパフォーマンスと一致しただけなので、絶好調というわけではありません。 - これらのシステムの BIOS では、4 つの異なるハードウェア プリフェッチャを有効/無効にできます (MLC Streamer Prefetcher、MLC Spatial Prefetcher、DCU Streamer Prefetcher、および DCU IP Prefetcher)。それぞれを無効にしてみましたが、そうすることでせいぜいパフォーマンス パリティを維持する程度で、いくつかの設定ではパフォーマンスが低下しました。
- 実行中の平均電力制限 (RAPL) DRAM モードを無効にしても、影響はありません。
-
私は、Fedora 19 (glibc 2.17) を実行している他の Supermicro システムにアクセスすることができます。Supermicro X9DRG-HF ボード、Fedora 19、および Xeon E5-2670 CPU で、上記と同様のパフォーマンスが確認されました。Supermicro X10SLM-F シングルソケットボードで Xeon E3-1275 v3 (Haswell) と Fedora 19 を使用した場合、9.6 GB/s で動作しました。
memcpy(104ms) です。Haswell システムの RAM は DDR3-1600 です (他のシステムと同じです)。
更新情報
-
BIOS で CPU の電源管理を Max Performance に設定し、ハイパースレッディングを無効にしました。ベースは
/proc/cpuinfoに基づいて、コアは 3 GHz でクロックされました。しかし、これは奇妙なことに、メモリ パフォーマンスを約 10% 低下させました。 - memtest86+ 4.10 は、メイン メモリへの帯域幅を 9091 MB/s と報告しています。これが読み取り、書き込み、またはコピーに対応するのかどうかは分かりませんでした。
- は STREAMベンチマーク はコピーについて 13422 MB/s と報告していますが、バイトを読み取りと書き込みの両方としてカウントしているので、上記の結果と比較したい場合は ~6.5 GB/s に相当します。
関連
-
[解決済み】「corrupted size vs. prev_size」glibc エラーを理解する。
-
[解決済み】エラー。switchステートメントでcaseラベルにジャンプする
-
[解決済み】c++で.txtファイルから2次元の配列に読み込む
-
[解決済み] Linuxで特定のテキストを含むすべてのファイルを検索するにはどうすればよいですか?
-
[解決済み] SQLiteのINSERT/per-secondのパフォーマンスを向上させる
-
[解決済み] Linux上で動作するC++コードのプロファイリングを行うにはどうすればよいですか?
-
[解決済み] LinuxのシェルスクリプトでYes/No/Cancelの入力を促すにはどうしたらいいですか?
-
[解決済み] 0.1fを0にすると、なぜ10倍もパフォーマンスが落ちるのですか?
-
[解決済み] Linux で grep を使ってファイル名だけを表示するにはどうしたらいいですか?
-
[解決済み] Cプリプロセッサはなぜ "linux "という単語を定数 "1 "と解釈するのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】LLVMで暗黙のうちに削除されたコピーコンストラクタの呼び出し
-
[解決済み】致命的なエラー LNK1169: ゲームプログラミングで1つ以上の多重定義されたシンボルが発見された
-
[解決済み】関数名の前に期待されるイニシャライザー
-
[解決済み] クラスにデフォルトコンストラクタが存在しない。
-
[解決済み】'cout'は型名ではない
-
[解決済み】エラー:不完全な型へのメンバーアクセス:前方宣言の
-
[解決済み] [Solved] インクルードファイルが開けません。'stdio.h' - Visual Studio Community 2017 - C++ Error
-
[解決済み】指定範囲内の乱数で配列を埋める(C++)
-
[解決済み】デバッグアサーションに失敗しました
-
[解決済み】変数やフィールドがvoid宣言されている