URLを入力したときにバックグラウンドで起こること
ブラウザ、HTTP、HTML、Webサーバー、要件処理など、Webアプリケーションがどのように動作するか、その技術を含む完全な階層的な視点を持つことが、ソフトウェア開発者として必要です。
この記事では、URLを入力するときにバックグラウンドで何が起こっているのかを深く掘り下げていきます ~。
1. まず、ブラウザにURLを入力する必要がある :


ナビゲーションの最初のステップは、訪問したドメインのIPアドレスをドメイン名で調べることである。DNSルックアップのプロセスは次のとおりである。
DNSの再帰的検索は次の図のようになります。
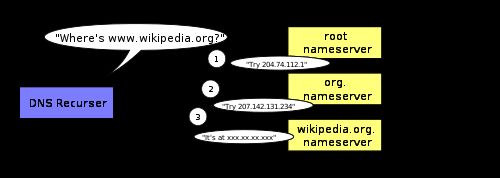
DNSの懸念事項の1つは、wikipedia.orgやfacebook.comなどのドメイン全体が、1つのIPアドレスにしか対応していないように見えることです。幸いなことに、このボトルネックを解消する方法がいくつかあります。
サイクリックDNS は、DNSルックアップが複数のIPを返す場合の解決策です。例として、Facebook.comは実際には4つのIPアドレスに対応しています。ロードバランサーは、特定のIPアドレスでリッスンし、ネットワーク要求をサーバーのクラスタに転送するハードウェアデバイスです。一部の大規模サイトでは、このような高価で高性能なロードバランサーを使用するのが一般的です。地理 DNS ユーザーの地理的な位置に応じて、ドメイン名を複数の異なるIPアドレスにマッピングすることで、スケーラビリティを向上させる。この方法では、異なるサーバーが同期状態を更新することはできませんが、静的コンテンツをマッピングすることは非常に優れています。 エニーキャスト は、1つのIPアドレスを複数の物理ホストにマッピングするルーティング技術である。欠点として、AnycastはTCPプロトコルとうまく動作しないため、そのようなシナリオで使用されることはほとんどありません。ほとんどのDNSサーバーは、効率的で低遅延のDNSルックアップを得るためにエニーキャストを使用しています。
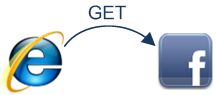
Facebookのページのような動的なページは、開いた直後にブラウザのキャッシュで失効するため、そこから読み出すことができないのは間違いないでしょう。
そこで、ブラウザはFacebookがあるサーバーに次のようなリクエストを送ります。
GET http://facebook.com/ HTTP/1.1Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]Accept-Encoding: gzip, deflateConnection: Keep-AliveHost: facebook.comCookie: datr=1265876274-[...] ; locale=en_US; lsd=WW[...] ; c_user=2101[...]
GET このリクエストは URL : "http://facebook.com/"。ブラウザ自身が定義している( ユーザーエージェント ヘッダ)、そしてどのような種類の対応を期待するか( 受理 と Accept-Encoding ヘッダ)。 接続方法 ヘッダは、それ以降のリクエストに対してTCPコネクションを閉じないようサーバーに要求します。
また、リクエストには、ブラウザに保存されている クッキー . すでにご存知のことと思いますが、クッキーは、異なるページのリクエストにおいて、トラッキングサイトのステータスを一致させるキーです。クッキーは、テキストファイルとしてクライアントに保存され、リクエストごとにサーバーに送信されます。
生のHTTPリクエストを見るために使われるツールや、それに対応するツールはたくさんあります。筆者はfiddlerを好んで使っていますが、もちろんFireBugのような他のツールもあります。これらのプログラムは、サイトを最適化する際にとても役に立ちます。
フェッチリクエストの他に、フォーム送信の際によく使われるセンドリクエストがあります。送信リクエストは、パラメータをURLで渡します(例:http://robozzle.com/puzzle.aspx?id=85)。送信リクエストは、リクエストボディヘッダの後にパラメータを送信します。
"http://facebook.com/"のようなスラッシュは重要です。この場合、ブラウザは安全にスラッシュを追加することができます。http: //example.com/folderOrFile"のようなアドレスの場合、folderOrFileがフォルダなのかファイルなのかが不明なため、ブラウザは自動的にスラッシュを付けません。この場合、ブラウザはスラッシュを付けずにアドレスにアクセスし、サーバーはリダイレクトで応答するため、不要なハンドシェイクが発生してしまいます。
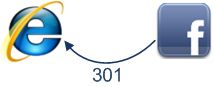
Facebookサーバーからブラウザに返されるレスポンスは図の通りです。
HTTP/1.1 301 Moved PermanentlyCache-Control: private, no-store, no-cache, must-revalidate, post-check=0,pre-check=0Expires: Sat, 01 Jan 2000 00:00:00 GMTLocation: http://www.facebook.com/P3P: CP="DSP LAW"Pragma: no-cacheSet-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;path=/; domain=.facebook.com; httponlyContent-Type: text/html; charset=utf-8X-Connection: closeDate: Fri, 12 Feb 2010 05:09:51 GMTContent-Length: 0
サーバーはブラウザに301の永久リダイレクトレスポンスを返すので、ブラウザは"http://facebook.com/"の代わりに"http://www.facebook.com/"を訪問します。
なぜサーバーは、ユーザーが見たいページの内容を直接送るのではなく、リダイレクトする必要があるのでしょうか?この問いには、多くの興味深い答えがあります。
理由のひとつは、検索エンジンのランキングに関係しています。ほら、あるページに http://www.igoro.com/ と http://igoro.com/ のように2つのアドレスがあると、検索エンジンはそれらを2つのサイトだと思い、結果としてそれぞれへの検索リンクが少なくなり、順位が下がります。そして、検索エンジンは301パーマネントリダイレクトの意味を知っているので、wwwのあるアドレスへの訪問とないアドレスへの訪問は、同じサイトランキングの下にまとめられるのです。
もうひとつは、アドレスを使い分けることでキャッシュフレンドリーが悪化することです。ページ名が複数ある場合、キャッシュに何度も表示されることがあります。
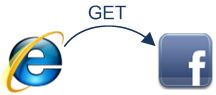
ブラウザは、"http://www.facebook.com/" が訪問する正しいアドレスであることを認識したので、別の取得要求を送信します。
GET http://www.facebook.com/ HTTP/1.1Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]Accept-Language: en-USUser-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...])Accept-Encoding: gzip, deflateConnection: Keep-AliveCookie: lsd=XW[...] ; c_user=21[...] ; x-referer=[...]Host: www.facebook.com
ヘッダーは前のリクエストと同じ意味です。
6. サーバーはリクエストを処理します。

サーバーはフェッチリクエストを受信した後、それを処理してレスポンスを返します。
一見すると簡単な作業のように見えますが、この間には興味深いことがたくさんあります。著者のブログのようなシンプルなサイトならともかく、Facebookのように多くの人が訪れるサイトでは、このようなことが行われているのです。
ウェブサーバソフトウェアWebサーバーソフトウェア(IISやApacheなど)は、HTTPリクエストを受信した後、どのようなリクエスト処理を行うかを決定して処理します。リクエストハンドラとは、リクエストを読み取り、応答するためのHTMLを生成することができるプログラム(ASP.NET、PHP、Rubyなど)......です。
最も単純な例として、リクエスト処理はウェブサイトのアドレス構造をマッピングしたファイルレベルで保存することができます。http://example.com/folder1/page1.aspx这个地 のようなファイルは /httpdocs/folder1/page1.aspx をマップすることになります。ウェブサーバソフトウェアはアドレスに対応するマニュアルとしてリクエストを処理するようにセットアップされ、page1.aspx は http: //example.com/folder1/page1 で公開されるようにすることが可能です。
リクエスト処理リクエストハンドラは、リクエストとそのパラメータ、Cookieを読み込み、いくつかのデータを読み込み、場合によっては更新してサーバーに保存します。そして、リクエスト処理によって HTML レスポンスが生成される。
動的なウェブサイトはすべて、データをどのように保存するかという興味深い難題に直面しています。小規模なサイトの半数はデータを保存するためにSQLデータベースを持っていますが、多くのデータを保存するサイトや多くの訪問者がいるサイトは、複数のマシンにデータベースを分散させる方法を見つけなければなりません。解決策としては、シャーディング(主キーの値に基づいて複数のデータベースにデータテーブルを分散させる)、レプリケーション、弱い意味的一貫性を利用したデータベースの簡素化などがあります。
バッチに仕事を任せることは、データを最新に保つための安価なテクニックである。例えば、Fackbookはニュースフィードを最新の状態に保つ必要がありますが、データに裏付けられた"people you might know"機能は毎晩更新する必要があるだけです(著者はそう推測していますが、この機能がどの程度改善されているのかは不明です)。バッチジョブの更新は、あまり重要でないデータを陳腐化させる可能性がありますが、データのファーミングをより速く、よりきれいにすることができます。
サーバーが生成して返したレスポンスは図の通りです。
HTTP/1.1 200 OKCache-Control: private, no-store, no-cache, must-revalidate, post-check=0,pre-check=0Expires: Sat, 01 Jan 2000 00:00:00 GMTP3P: CP="DSP LAW"Pragma: no-cacheContent-Encoding: gzipContent-Type: text/html; charset=utf-8X-Connection: closeTransfer-Encoding: chunkedDate: Fri, 12 Feb 2010 09:05:55 GMT2b3Tn@[...]
レスポンス全体のサイズは35kBで、そのほとんどが照合後にblob型として転送されます。
コンテンツのエンコーディング このヘッダーは、レスポンスボディ全体が gzip アルゴリズムで圧縮されていることをブラウザに伝えます。blobブロックを解凍すると、次のような期待されるHTMLが表示されます。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"lang="en" id="facebook" class=" no_js"><head><meta http-equiv="Content-type" content="text/html; charset=utf-8" /><meta http-equiv="Content-language" content="en" />...
圧縮については、ページをキャッシュするかどうか、キャッシュする場合はどのようにするか、設定するクッキー(この前のレスポンスにはない)、プライバシー情報などをヘッダーで説明しています。
なお、このヘッダーでは コンテンツタイプ を"に変換します。 テキスト/html "です。このヘッダーは、レスポンスをファイルとしてダウンロードするのではなく、HTMLとしてレンダリングするようにブラウザに指示します。ブラウザは、ヘッダー情報に基づいてレスポンスをどのように解釈するかを決定しますが、URL拡張子の内容など他の要素も考慮します。
ブラウザは、HTML文書全体を完全に受け入れる前に、ページの表示を開始します。
ブラウザはHTMLを表示する際、他のアドレスのコンテンツを取得する必要があるタグに気づきます。その時点で、ブラウザはそれらのファイルを再取得するためにフェッチ・リクエストを送信します。
ここに、facebook.comにアクセスした際に再取得が必要なURLがいくつかあります。
画像http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
... CSSスタイルシート
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
... JavaScriptファイル
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
...
これらのアドレスはすべて、HTMLの読み込みと同じようなプロセスを経ます。つまり、ブラウザはDNSでこれらのドメインを検索し、リクエストを送信し、リダイレクトする...というわけです。
しかし、動的なページと違って、静的なファイルはブラウザにキャッシュさせることができるようになります。ファイルによっては、サーバーと通信することなく、キャッシュから直接読み込むことができるものもあります。サーバーからの応答には、静的ファイルの保存期間に関する情報が含まれているので、ブラウザはどれくらいの期間キャッシュすればよいかがわかります。また、各レスポンスにはバージョン番号のように動作するETagヘッダ(要求された変数の実体値)が含まれている場合があり、ブラウザはファイルのバージョンETag情報が既に存在することを観測すると、そのファイルの転送を直ちに停止します。
推測してみてください" fbcdn.net "は、このアドレスの略でしょうか?賢明な答えは、"Facebook Content Delivery Network"です。Facebookは、画像、CSSテーブル、JavaScriptファイルなどの静的ファイルを配信するために、コンテンツ配信ネットワーク(CDN)を使用しています。つまり、これらのファイルは、世界中の多くのCDNのデータセンターにバックアップされたままになっているのです。
静的コンテンツは、サイトの帯域幅の大きさを表すことが多く、またCDNを通じて簡単に複製することができます。多くの場合、サイトはサードパーティのCDNを使用しています。たとえば、Facebookの静的ファイルは、最大のCDNプロバイダーであるアカマイによってホスティングされています。
例えば、static.ak.fbcdn.netにpingを打つと、akamai.netのサーバーの1つから応答が返ってくることがあります。興味深いことに、同じサーバーにもう一度pingを打つと、応答が異なる場合があります。これは、舞台裏での負荷分散が機能し始めていることを示します。
Web2.0の偉大な精神に則り、ページが表示された後もクライアントはサーバーとコンタクトを取り続ける。
たとえば、Facebookのチャット機能は、明るいグレーの友達のステータスを最新の状態に保つために、サーバーと常に連絡を取り合っています。アバターがついた友達のステータスを更新するために、ブラウザで実行されるJavaScriptのコードは、サーバーに非同期リクエストを送信しています。この非同期リクエストは、特定のアドレスに送信され、プログラム的に構築された取得または送信リクエストとなります。Facebookの例では、クライアントがオンライン状態の情報をhttp://www.facebook.com/ajax/chat/buddy_list.php一个发布请求来获取你好友里哪个。
このパターンといえば、quot;AJAX" - "Asynchronous JavaScript and XML" ですが、サーバーがXML形式で応答する明確な理由があるわけではないのです。別の例を挙げると、非同期のリクエストに対して、FacebookはいくつかのJavaScriptのコードスニペットを返します。
中でもfiddlerは、ブラウザから送られてくる非同期リクエストを見ることができるツールです。実際、これらのリクエストの受動的な視聴者になるだけでなく、能動的に修正したり再送信したりすることも可能です。(もちろん、そんな嘘はいけませんよ〜)
Facebookのチャット機能は、AJAXに関する興味深い問題事例を提供しています。サーバーサイドからクライアントへデータをプッシュすることです。HTTP はリクエストとレスポンスのプロトコルなので、チャットサーバーはクライアントに新しいメッセージを送ることができません。代わりに、クライアントはサーバーに新しいメッセージがあるかどうか、数秒ごとにポーリングする必要があります。
ロングポーリングは、このような状況が発生したときに、サーバーの負荷を軽減するための興味深いテクニックです。サーバーは、ポーリングされたときに新しいメッセージがなければ、クライアントを無視します。そして、タイムアウトする前にそのクライアントから新しいメッセージを受信すると、サーバーは未処理のリクエストを見つけ、クライアントへの応答として新しいメッセージを返します。
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン